
Claude Sonnet 5: The Cheaper-Than-Flagship Model That Makes You Manage Cost
Anthropic's mid-tier model now rivals the flagship on most benchmarks — if you manage the effort level.
Claude Sonnet 5: The Cheaper-Than-Flagship Model That Makes You Manage Cost
Claude Sonnet 5 is the first model in Anthropic's history where the mid-tier genuinely competes with the flagship on most intelligence benchmarks — but the cost advantage only materializes if you actively manage its effort level. Miss that detail and you could pay more per task than you would for Opus 4.8.
Released June 30, 2026, Claude Sonnet 5 represents a genuine inflection point in the Anthropic lineup. Not because it unseats Opus 4.8 as the absolute best — it doesn't, quite — but because for a wide class of real-world agentic work, it delivers comparable intelligence at roughly 40% lower cost per token. The catch is that Sonnet 5 ships with adaptive thinking always enabled and a new tokenizer that produces more tokens per task. In the wrong configuration, that can flip the cost equation entirely.
This post goes beyond the spec sheet: how to think about Sonnet 5 in context, when it's genuinely the right pick, when it isn't, and what the "effort level trap" actually means in practice.
What Is Claude Sonnet 5?
Claude Sonnet 5 (claude-sonnet-5) is Anthropic's mid-tier model released June 30, 2026, succeeding Claude Sonnet 4.6. It sits third in the current family tier:
Fable 5 > Opus 4.8 > Sonnet 5 > Haiku 4.5
Anthropic's positioning is deliberate: "performance close to Opus 4.8 at lower prices." The benchmark data largely backs that up — and in some evaluations, Sonnet 5 draws level with or narrowly edges the flagship. The 1-million-token context window, adaptive thinking, and strong agentic tool use put it in a different category from its predecessor.
The Benchmarks: Where Sonnet 5 Actually Stands
The headline numbers from Anthropic's model overview are worth reading carefully, because the story isn't "Sonnet 5 is almost as good as Opus 4.8" — it's more nuanced than that.
| Benchmark | Sonnet 4.6 | Sonnet 5 | Opus 4.8 |
|---|---|---|---|
| SWE-bench Verified | 79.6% | 85.2% | 88.6% |
| SWE-bench Pro | — | 63.2% | — |
| FrontierCode | 15.1% | 38.8% | — |
| Terminal-Bench 2.1 | — | 80.4% | ~82.7%* |
| GDPval-AA (knowledge work Elo) | — | 1618 | 1615 (≈tie) |
| Humanity's Last Exam (with tools) | — | 57.4% | ~57.9% (near-tie) |
Opus 4.8's Terminal-Bench 2.1 score is reported anywhere from ~74.6% to 82.7% depending on the harness, so the two are best read as level rather than one clearly beating the other.
The FrontierCode number is the most striking: Sonnet 5 more than doubles Sonnet 4.6's score (15.1% → 38.8%). That's not incremental progress; that's a qualitative jump in complex code generation. On GDPval-AA — which measures the multi-step, judgment-heavy knowledge work that defines modern agentic pipelines — Sonnet 5 (1618) lands level with Opus 4.8 (1615), and on Terminal-Bench 2.1 it is competitive with the flagship rather than clearly behind it.
Independent evaluation from Artificial Analysis places Sonnet 5 at an Intelligence Index of 53, ranking #5 overall. Their more important finding: cost-per-task is approximately $2.29, which is actually about 15% more expensive than Opus 4.8 on equivalent tasks. We'll come back to why that matters enormously.
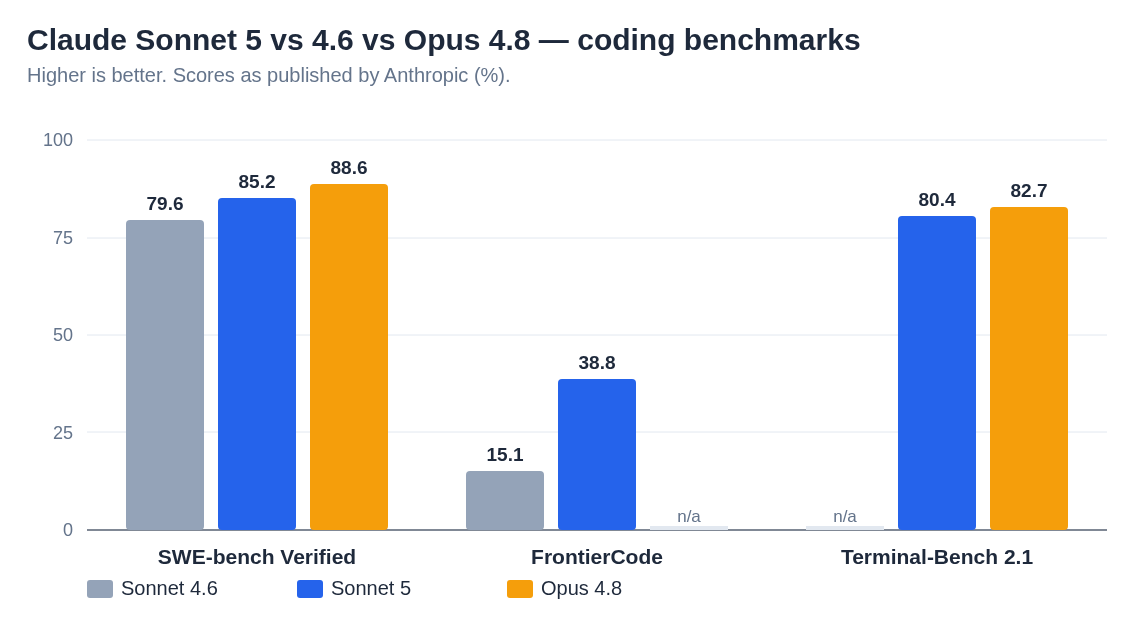 Sonnet 5 closes the gap to flagship on most benchmarks and draws level with Opus 4.8 on terminal and knowledge-work benchmarks. FrontierCode shows the most dramatic improvement over Sonnet 4.6.
Sonnet 5 closes the gap to flagship on most benchmarks and draws level with Opus 4.8 on terminal and knowledge-work benchmarks. FrontierCode shows the most dramatic improvement over Sonnet 4.6.
The Feature That Changes Everything: Adaptive Thinking
Every previous Anthropic model treated extended thinking as an opt-in feature. Sonnet 5 makes it mandatory. Adaptive thinking is always on, and you control its depth through five effort levels:
- low — minimal reasoning, fastest, cheapest
- medium — light reasoning pass
- high (default) — the setting most benchmarks use
- xhigh — deep reasoning, significantly more output tokens
- max — maximum reasoning budget
This design decision is the core of the cost management challenge. At high (default), Sonnet 5 at its September standard pricing of $3/M input and $15/M output is clearly cheaper than Opus 4.8 ($5/$25) for most tasks. But at xhigh or max, the token output expands substantially — and combined with the new tokenizer (shared with Opus 4.7, 4.8, and Fable 5) that produces roughly 1.0–1.35x more tokens than older tokenizers, you can watch a Sonnet 5 task exceed the cost of the equivalent Opus 4.8 call.
The Zapier engineering team noted something interesting: at low effort, Sonnet 5 already beats Sonnet 4.6 running at any effort level, and costs less. That's the "cheap workhorse" case. Simple retrieval, summarization, light classification, routing tasks — low effort on Sonnet 5 is the new default for cost-conscious builders.
The Real Cost Picture: Intro Period and What Comes After
Pricing has two phases:
| Period | Input | Output | Notes |
|---|---|---|---|
| Intro (through Aug 31, 2026) | $2/M | $10/M | Use this window |
| Standard (from Sep 1, 2026) | $3/M | $15/M | Standard tier |
| Prompt cache reads | Up to 90% off | Up to 90% off | Highly effective for repeated context |
| Batch API | 50% off | 50% off | 300k output context in beta |
The intro period matters. Agentic workloads running now on Sonnet 5 cost $2/$10 — 33% cheaper than standard. If you're building a pipeline, this is the time to test and optimize at low marginal cost before the September pricing kicks in. The Anthropic Sonnet page has current pricing details.
One underappreciated feature: prompt caching up to 90% off makes Sonnet 5 extremely efficient for the kind of long-context agentic work where you're repeatedly reading the same repository, document set, or tool schema. For those patterns, effective cost can drop well below the headline numbers.
Sonnet 5 vs. Opus 4.8 vs. Haiku 4.5: A Real Decision Framework
The standard advice — "use the flagship for hard tasks, the mid-tier for medium tasks, the small model for simple tasks" — breaks down with Sonnet 5. The benchmark data forces a more granular view.
When Sonnet 5 is clearly the right call
Agentic coding and terminal work. Sonnet 5 scores 80.4% on Terminal-Bench 2.1 — level with Opus 4.8 rather than clearly behind — and its FrontierCode score more than doubled from the prior generation. For the kind of end-to-end coding agents — write, run, check output, iterate — that now define production AI workflows, Sonnet 5 holds up. The Zapier team specifically highlighted that agentic tasks that "used to stall" in earlier models now complete end-to-end. It also reportedly "checks its own output without being asked," which reduces the need for explicit verification loops.
Knowledge work and research pipelines. The GDPval-AA Elo of 1618 (vs. Opus 4.8's 1615) is essentially a statistical tie — the point being that Sonnet 5 gives up little to no knowledge-work quality to save money. For research summarization, document processing, and multi-step reasoning over long contexts — especially with the 1M token window — Sonnet 5 at high effort holds its own against the flagship.
Anything requiring the 1M context window. Both Sonnet 5 and Opus 4.8 offer 1-million-token context. But at Sonnet 5 pricing, running a 500k-token codebase analysis costs substantially less per call.
High-volume API production. At standard pricing, Sonnet 5 is 40% cheaper per token than Opus 4.8. At scale, that compounds fast.
When Opus 4.8 is still worth it
Tasks where output quality variance matters more than average quality. The SWE-bench Verified gap (85.2% vs. 88.6%) is 3.4 points. In practice, that means Opus 4.8 gets a higher fraction of hard coding tasks right. For irreversible actions, compliance-sensitive workflows, or tasks where a wrong answer costs more than the API delta, pay for the flagship.
When you need guaranteed ceiling performance. Sonnet 5 on average rivals Opus 4.8 — but Opus 4.8 is more consistently at the top of its range. If you're doing one-shot critical analysis and can't easily iterate, Opus 4.8 still has the edge.
When Haiku 4.5 is the obvious answer
Routing, classification, lightweight summarization, simple Q&A, anything that runs 50+ times per user session. Claude Haiku 4.5 at $1/$5 is genuinely capable for these patterns, and Sonnet 5 at low effort doesn't justify the 3x price for simple tasks. Build a routing layer — use Haiku for volume, Sonnet 5 for mid-complexity, Opus 4.8 for the hard cases — and you'll cut costs substantially vs. a single-model approach.
The Effort-Level Cost Trap
This is the part of the Sonnet 5 story that most coverage misses entirely.
Adaptive thinking is always on. At max effort, Sonnet 5 can easily generate 2–3x the output tokens of the same task at low effort. Combined with the new tokenizer's 1.0–1.35x token inflation vs. older models, a developer who drops Sonnet 5 into a production pipeline with default (or high) effort and doesn't measure actual token counts could easily end up spending more per task than they would have with Opus 4.8 at a lower effort setting.
Artificial Analysis confirmed this empirically: cost-per-task for Sonnet 5 on their agentic benchmark suite was ~$2.29, roughly 15% more than Opus 4.8. That seems counterintuitive at first — how can the cheaper model cost more per task? The answer is token inflation from reasoning: the high default effort means Sonnet 5 is burning tokens on thinking that Opus 4.8 doesn't need to do (or does implicitly without generating as many reasoning tokens).
Practical guidance:
- Default to
lowfor anything that doesn't require multi-step reasoning. Atloweffort, Sonnet 5 still outperforms Sonnet 4.6 at any effort level on most benchmarks. - Use
high(default) for agentic tasks where reasoning quality matters. This is the setting the benchmarks use and where the Opus 4.8 comparisons hold. - Reserve
xhigh/maxfor genuinely hard problems — complex debugging, novel research, exam-quality reasoning. These are the only tasks where the extra token spend is defensible. - Measure actual token counts per task before launching to production. The new tokenizer means your Sonnet 4.6 cost estimates will be off.
For teams building on Happycapy or directly on the API, this isn't optional discipline — it's the difference between Sonnet 5 being 40% cheaper than Opus 4.8 or meaningfully more expensive. Start free at happycapy.ai to run side-by-side comparisons across effort levels before committing to a configuration.
What It's Actually Like to Use Sonnet 5
The claude.ai web app now uses Sonnet 5 as the default for both Free and Pro tiers. Initial community reception has been broadly positive on capability — with notable caveats.
What's working: Agentic follow-through is the most common praise. Engineers report that multi-step tasks that required human intervention points in Sonnet 4.6 now complete autonomously. The model self-verifies outputs more reliably — running a test, seeing it fail, fixing the code, and re-running without being explicitly instructed to do so. This reduces the scaffolding code you need to write for agentic pipelines.
What's frustrating: Over-refusal is the dominant complaint in the web UI. Some users describe it as "paranoid" guardrails that block reasonable creative or technical requests. It's worth noting that much of this behavior appears to be specific to the claude.ai system prompt rather than a documented model regression — developers using the API directly report fewer issues. Related: some users feel the model has lost a degree of warmth or distinct "personality" compared to earlier Sonnet versions.
The agentic over-reading problem: Sonnet 5's tendency to read large amounts of context before acting — reading "tens of thousands of lines for simple questions," per some reports — is real and stems directly from adaptive thinking always being on. The model tries to be thorough. In an agent with access to a large codebase, this can burn tokens fast. Constraining context access at the tool level is more effective than fighting the model's natural tendencies.
Context Window and Technical Specs
| Spec | Value |
|---|---|
| Context window | 1,000,000 tokens |
| Max output (standard) | 128,000 tokens |
| Max output (Batch API beta) | 300,000 tokens |
| Input modalities | Text + images |
| Output modalities | Text only |
| Knowledge cutoff | January 2026 |
| Adaptive thinking | Always on (5 levels) |
| API identifier | claude-sonnet-5 |
The 1M context window is matched only by Opus 4.8 in the current lineup. For use cases involving full-codebase analysis, long legal documents, or multi-document research synthesis, this is meaningful — and at Sonnet 5 pricing, large-context calls are substantially cheaper than the equivalent Opus 4.8 call.
No audio input or output is supported. Text and images in, text out.
Availability: Where to Run Sonnet 5
Sonnet 5 is available across essentially every major deployment channel:
- claude.ai — default model for Free and Pro tiers
- Anthropic API —
claude-sonnet-5model ID - Claude Code — available as the coding agent backend
- AWS Bedrock — deployed in supported regions
- Google Vertex AI — available via Vertex model garden
- Microsoft Foundry — available for enterprise deployments
- Happycapy — Sonnet 5 is one of 150+ models available in the browser-based sandbox
The Happycapy angle is worth highlighting for developers who want to evaluate Sonnet 5 against alternatives without managing API keys or infrastructure. You can run Sonnet 5 side-by-side with Opus 4.8, Haiku 4.5, and models from other providers — all with tool use, agent pipelines, and file access in a browser sandbox. For the effort-level testing described above, this kind of side-by-side environment is genuinely useful before you commit to a production configuration.
For builders working on Claude-native applications, see the Claude Code SDK and harness engineering guide for integration patterns, and agentic AI vs. AI agents for the conceptual framing of where Sonnet 5 fits in autonomous pipelines.
The Bottom Line: Intelligence-Per-Dollar, Managed
The framing that captures it best: Sonnet 5 overlaps the flagship tier at roughly 40% less per token at standard pricing. The benchmark data backs this up for most workloads. But the sentence that matters more is the one from Artificial Analysis: in practice, cost-per-task can be higher than Opus 4.8 if effort levels are unmanaged.
Sonnet 5 is the first Sonnet that earns genuine consideration against the flagship — not as a compromise, but as the default choice for a wide class of real work. The implication for builders is a shift in mental model: the hard question used to be "which model?" Now it's "which model at which effort level, and is my token instrumentation actually telling me the truth?"
That's a more demanding question. But it's also a sign that the mid-tier has genuinely grown up.
Start free at happycapy.ai to run Sonnet 5 alongside 150+ other models in a browser sandbox with full tool access — no API key required.
For comparisons across the current generation of coding-focused models, see our best AI agent for coding guide and Claude Code vs. Cursor breakdown.
FAQ: Claude Sonnet 5
What is Claude Sonnet 5?
Claude Sonnet 5 is Anthropic's mid-tier AI model released June 30, 2026. It's the third-most capable model in Anthropic's current lineup (behind Fable 5 and Opus 4.8) and features a 1-million-token context window, always-on adaptive thinking, and strong agentic coding performance. API identifier: claude-sonnet-5.
How does Claude Sonnet 5 compare to Opus 4.8?
On most benchmarks, Sonnet 5 comes close to Opus 4.8 and lands roughly level with it on terminal tasks and knowledge-work Elo. Sonnet 5 is priced at $3/M input and $15/M output vs. Opus 4.8's $5/$25. However, Sonnet 5's always-on adaptive thinking can make actual cost-per-task higher than expected — Artificial Analysis measured ~$2.29 per task, roughly 15% more than Opus 4.8, due to token output from reasoning. At controlled effort levels, Sonnet 5 is the better deal for most production workloads.
What is Claude Sonnet 5 pricing?
Through August 31, 2026: $2/M input tokens, $10/M output tokens (introductory pricing). From September 1, 2026: $3/M input, $15/M output. Prompt caching available for up to 90% savings on repeated context; Batch API (50% discount) supports up to 300k output tokens in beta.
Is Claude Sonnet 5 free to use?
Yes — Claude Sonnet 5 is the default model on claude.ai Free tier, so you can use it without paying. Usage limits apply on the free tier. On Happycapy, you can also run Sonnet 5 with a free account alongside 150+ other models in a browser sandbox with tool support.
What is Claude Sonnet 5's context window?
1,000,000 tokens (1M). Maximum output is 128,000 tokens for standard API calls, and up to 300,000 tokens via the Batch API beta.
How does Claude Sonnet 5 compare to Sonnet 4.6?
Substantially stronger across the board. SWE-bench Verified improved from 79.6% to 85.2%. FrontierCode more than doubled (15.1% → 38.8%). The context window expanded to 1M tokens. Adaptive thinking is now always on. Notably, Sonnet 5 at low effort already beats Sonnet 4.6 at any effort level on most tasks — and costs less per token.
What is adaptive thinking, and can I turn it off in Sonnet 5?
Adaptive thinking is Anthropic's extended internal reasoning feature — the model reasons through problems before responding. In Sonnet 5, it is always on and cannot be disabled. You control the depth via five effort levels (low/medium/high/xhigh/max), with high as the default. Higher effort levels generate more reasoning tokens and increase cost; low effort is the most cost-efficient setting for straightforward tasks.
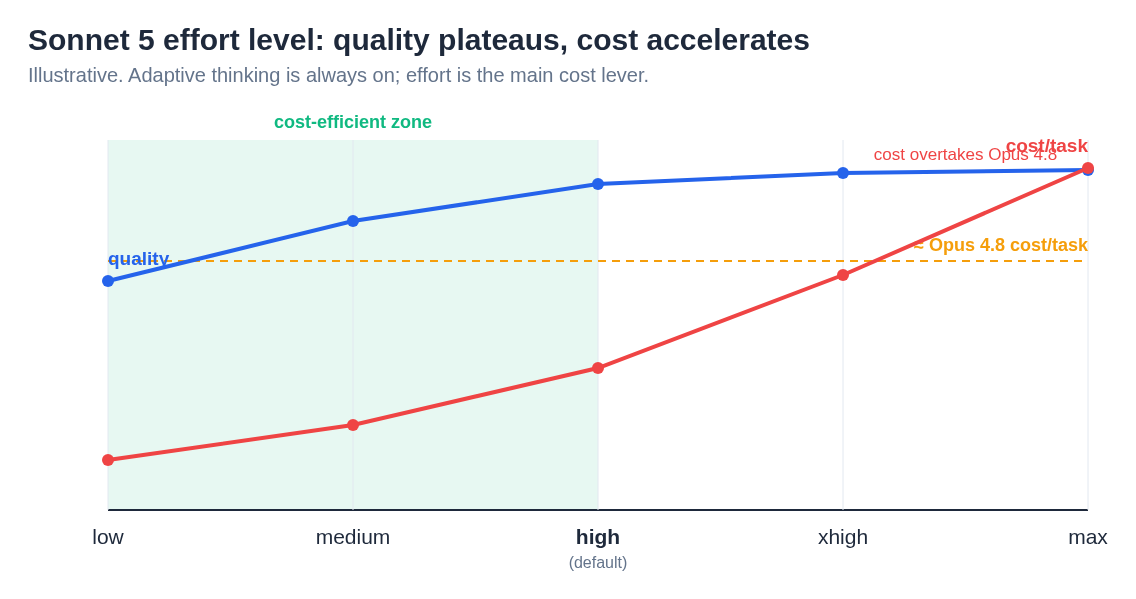 Effort level is the primary cost lever in Sonnet 5. At
Effort level is the primary cost lever in Sonnet 5. At low, it undercuts Sonnet 4.6 on both cost and quality. At xhigh/max, token inflation can push cost-per-task above Opus 4.8.

