
Claude Haiku 4.5: Anthropic's Fastest Model Explained
The fast, cheap powerhouse that makes AI agent loops economically viable — and why it matters more than its price tag suggests.
Claude Haiku 4.5: Anthropic's Fastest Model Explained
Claude Haiku 4.5 is Anthropic's fastest and most cost-efficient language model — the speed-optimized tier of the Claude 4 family, designed for high-throughput, low-latency workloads where calling a frontier-sized model every turn would be prohibitively slow or expensive. Released on October 15, 2025, it runs — according to Anthropic's launch announcement — up to four to five times faster than Claude Sonnet 4.5 at a fraction of the cost, making it the default workhorse inside agent loops, classification pipelines, and real-time developer tools. If you want every spec from Anthropic's own documentation, the canonical source is Anthropic's Claude Haiku page and the official pricing page.
What Is Claude Haiku 4.5?
Claude Haiku 4.5 is the third major model tier in Anthropic's Claude lineup, sitting below Sonnet and Opus in raw capability but well above earlier generations of "small" models in absolute terms. The Haiku name signals the design philosophy: concise, fast, economical — a haiku is the shortest recognized poetic form, and the model takes its identity from that framing.
What makes Haiku 4.5 notable is not that it is merely a stripped-down Sonnet. Anthropic describes it as delivering "near-frontier intelligence" — meaning that at release, its performance on agentic coding and computer-use benchmarks matched or exceeded what Sonnet 4 (the prior generation's balanced model) could achieve. The leap in efficiency per FLOP from generation to generation means each new Haiku is smarter than the previous one in absolute terms, even as it remains the cheapest tier in the current family.
The Release Context
Claude Haiku 4.5 was announced on October 15, 2025. It arrived several months after Sonnet 4.5 and Opus 4.1, rounding out the fourth generation of the Claude family. Anthropic framed the launch explicitly around agentic use: "Speed is the new frontier for AI agents operating in feedback loops," the announcement read, citing that Haiku's latency unlocks entire categories of production applications that were impractical at Sonnet prices and speeds.
Where Haiku 4.5 Sits in the Claude Family
 Qualitative positioning of Haiku 4.5, Sonnet, and Opus across the speed/cost vs capability spectrum. Axes are relative — no invented numbers.
Qualitative positioning of Haiku 4.5, Sonnet, and Opus across the speed/cost vs capability spectrum. Axes are relative — no invented numbers.
The Claude lineup follows a three-tier logic that Anthropic has maintained across generations:
- Haiku — fastest, lowest cost per token, optimized for high-throughput tasks where latency matters
- Sonnet — the balanced "default" for most developers, strong reasoning with reasonable speed
- Opus — maximum capability, deepest reasoning, most suitable for tasks requiring nuanced multi-step judgment
Haiku 4.5 occupies the fast/cheap tier, but the absolute capability floor of each tier rises with each generation. The practical implication: if you were previously routing certain tasks to Sonnet 3.x because Haiku 3.5 was not good enough, you may find Haiku 4.5 sufficient — at a lower price point.
Anthropic prices Haiku 4.5 at $1.00 per million input tokens and $5.00 per million output tokens (anthropic.com/pricing); third-party aggregators such as OpenRouter and CloudPrice report the same figures as of mid-2026. Anthropic also documents up to 90% cost savings through prompt caching and 50% savings through batch processing. Always verify current pricing directly at the source, as rates can change.
Verified Technical Specs
Below are specifications Anthropic has confirmed through its official channels and launch materials. I note where I am relying on third-party aggregators versus Anthropic's own pages.
| Spec | Value | Source |
|---|---|---|
| Context window | 200,000 tokens | Anthropic (confirmed on launch page) |
| Max output tokens | 64,000 tokens | Anthropic (confirmed) |
| Modalities | Text + image input; text output | Anthropic (confirmed) |
| Extended thinking | Yes (new to Haiku family in 4.5) | Anthropic (confirmed) |
| Computer use | Yes (new to Haiku family in 4.5) | Anthropic (confirmed) |
| Tool / function calling | Yes | Anthropic (confirmed) |
| Structured outputs (JSON schema) | Yes | Anthropic (confirmed) |
| Prompt caching | Yes | Anthropic (confirmed) |
| Knowledge cutoff | July 1, 2025 | Anthropic (confirmed) |
| API pricing (input) | $1.00 / 1M tokens | Multiple third-party aggregators + Anthropic pricing page |
| API pricing (output) | $5.00 / 1M tokens | Multiple third-party aggregators + Anthropic pricing page |
| Safety tier | ASL-2 | Anthropic system card (October 2025) |
Specs I could NOT independently verify from Anthropic's own docs (present in third-party sources but I have not seen them in official documentation):
- Exact tokens-per-second throughput figures (146 completions/second figures come from third-party benchmarks, not Anthropic docs)
- Any specific latency numbers in milliseconds (third-party benchmarks vary by provider and load)
- Benchmark percentile rankings against non-Claude models (I will describe what Anthropic reported but will not assert relative rankings against GPT or Gemini without Anthropic citation)
For benchmarks Anthropic itself reported: on SWE-bench Verified (agentic coding on real GitHub repositories), Haiku 4.5 scored 73.3%, averaged over 50 runs with a two-tool scaffold. Anthropic stated this was comparable to Sonnet 4's coding performance at Haiku's price and speed. This figure appears in the official launch announcement at anthropic.com/news/claude-haiku-4-5.
What Haiku 4.5 Is Good At
High-Throughput Classification and Extraction
The most economically transformative use case for Haiku 4.5 is mass classification. Think: routing ten thousand support tickets per hour into categories, extracting structured fields from unstructured documents, labeling product descriptions, or triaging incoming signals in a financial monitoring system. These tasks share a pattern: each call is relatively short, the output is compact, and accuracy needs to be "good enough" rather than perfect — because volume and cost matter more than perfection on any single item.
At $1.00 / million input tokens, a system that processes a million short documents (average 500 tokens each) in a day costs $500 in input tokens — versus $3,000 for the same volume on Sonnet. That 6× cost difference is frequently decisive in production budgets.
Low-Latency Interactive Agents
Real-time conversational agents — customer support bots, coding assistants, inline IDE completions — live or die by perceived latency. Users tolerate a 200ms response; they notice a 2-second wait. Because Haiku 4.5 runs 4–5× faster than Sonnet 4.5 (per Anthropic's launch figures), it can service interactive conversations with the feel of an instantaneous response even under production load.
Anthropic notes that tools like Claude Code, GitHub Copilot integrations, and Warp use Haiku 4.5 as the model for fast in-loop suggestions and coding sub-tasks precisely for this reason.
Sub-Tasks in Multi-Agent Pipelines
This is arguably Haiku 4.5's most strategically important role, and we will examine it closely in the section below. In an agent loop, the expensive model (Sonnet or Opus) handles high-level planning while Haiku handles the individual execution steps: running a bash command, parsing the output, making a single tool call, checking a condition, formatting a result. Each of those steps might take 500–2,000 tokens. At Haiku pricing, thousands of those micro-calls per hour remain economically viable. At Opus pricing, they do not.
Computer Use
Haiku 4.5 is the first Haiku-generation model to support computer use — the capability that lets a model operate a browser, desktop application, or GUI environment by interpreting screenshots and emitting cursor/keyboard actions. This is significant because computer-use tasks are naturally iterative: the model looks at the screen, takes one small action, looks again, takes another action. Each iteration is a separate model call. Haiku's cost and latency profile makes those iterations cheap and fast; the same loop on Opus would be orders of magnitude more expensive.
Extended Thinking (New in Haiku 4.5)
Haiku 4.5 is also the first Haiku-generation model to support extended thinking — the ability to emit an internal reasoning chain before generating the final response. This is valuable for tasks that benefit from step-by-step deliberation but where you still want Haiku's speed and price rather than reaching for Sonnet. Note that thinking tokens are billed at output token rates ($5.00 / million), so extended thinking should be used selectively on tasks where it genuinely improves accuracy.
A Worked Agent-Loop Example: Haiku as the Right Call
Here is a concrete scenario that illustrates where Haiku 4.5 is the correct choice and where you should escalate.
Scenario: A developer asks an AI coding assistant to "refactor all Python files in this repository to use pathlib instead of os.path."
Step 1 — Planning (Sonnet or Opus)
The orchestrating model receives the request, understands the scope, decides to enumerate all .py files, creates a plan for what needs to change, and sets up a task queue. This step requires understanding intent, evaluating trade-offs, and making judgment calls about edge cases. This is Sonnet territory.
Steps 2–N — Execution (Haiku 4.5)
For each file in the repository:
- Read the file content (tool call)
- Identify lines using
os.path(pattern match / short extraction task) - Emit the rewritten file content (focused text generation)
- Write the result (tool call)
- Report success or flag an edge case back to the orchestrator
Each of these steps is short, focused, and repeatable. There is no need for deep multi-hop reasoning. The output is deterministic enough that correctness can be verified mechanically. This is Haiku 4.5 territory.
When to Escalate Back
If step 2 finds a particularly gnarly piece of code — deeply nested calls, dynamic path construction, third-party library interactions — the sub-agent can flag it and route that specific file back up to Sonnet for human-level judgment. The orchestrator decides whether to apply a best-effort Haiku edit or hold the file for manual review.
This pattern — Sonnet plans, Haiku executes, escalate edge cases — is exactly what Anthropic describes as the intended production architecture. It is also referenced in our deep dive on context engineering for AI agents, which covers how to structure context across multi-agent systems so each model receives only what it needs.
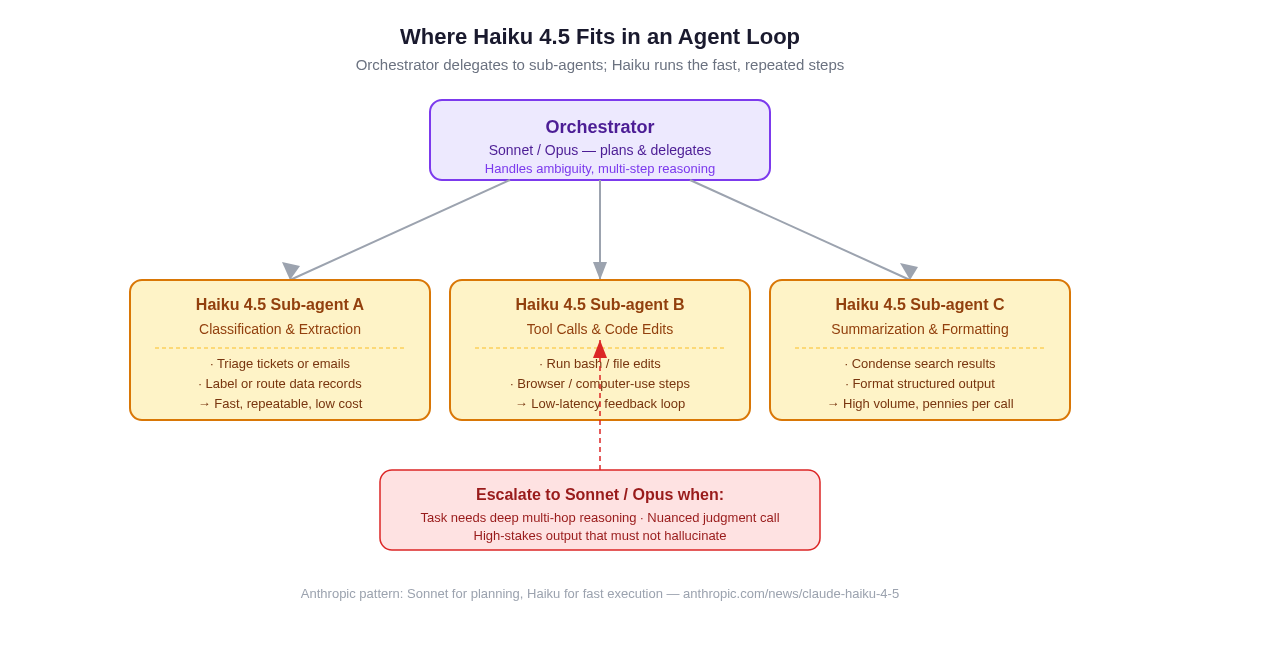 In a typical multi-agent loop, Haiku 4.5 handles the fast, repeated sub-tasks while Sonnet or Opus manages planning and escalation.
In a typical multi-agent loop, Haiku 4.5 handles the fast, repeated sub-tasks while Sonnet or Opus manages planning and escalation.
Cost and Latency Reasoning
When the Numbers Actually Matter
A useful mental model: every 1,000 tokens of input costs $0.001 on Haiku 4.5 and $0.003 on Sonnet. For a single call, that difference is negligible. For a system processing 50,000 calls per day, the difference is $50/day vs $150/day — $18,000/year vs $54,000/year. At scale, picking the right model for each task is a real engineering decision, not a theoretical one.
Prompt caching amplifies this further. If your agent loop passes the same system prompt or tool definitions on every call, prompt caching on Haiku 4.5 reduces the cost of those cached tokens by up to 90%. A 10,000-token system prompt cached at $0.10/million on re-reads costs virtually nothing across thousands of turns.
Latency as a Product Decision
For interactive use cases, latency is not just an engineering metric — it is a product quality metric. An agent that responds in under a second feels intelligent and responsive. One that takes 3–5 seconds per step — even if each answer is slightly better — often feels broken. Haiku 4.5's speed advantage directly translates to better user experience in chat interfaces, IDE integrations, and any real-time agentic surface.
Batch Processing for Non-Realtime Workloads
For workloads that are not time-sensitive — overnight data processing, bulk classification, async document analysis — Anthropic offers batch processing at up to 50% cost reduction. Combined with Haiku 4.5's already-low base price, this makes large-scale AI data processing economically viable at scales that were not practical even a year ago.
When NOT to Use Haiku 4.5
Haiku 4.5's speed and cost advantages come with genuine trade-offs. Here is where you should reach for Sonnet or Opus instead:
Deep multi-step reasoning. Tasks that require the model to hold a long chain of dependencies in working memory, reason through logical contradictions, or produce genuinely novel synthesis from disparate sources tend to benefit from larger models. Haiku's reasoning ability is strong for its tier but it can drop steps or miss subtle logical connections on highly complex problems.
High-stakes outputs. Legal document drafting, medical information synthesis, financial advice, or any output where a hallucination has material consequences calls for a model with higher accuracy on nuanced factual tasks. Route these to Sonnet or Opus and use Haiku for the surrounding scaffolding.
Tasks requiring extended context. Both Haiku 4.5 and Sonnet 4.5 share a 200,000-token context window, so this is less of a differentiator at model level. But if your task involves complex reasoning across a very long context — synthesizing a 150K-token document into a nuanced strategic recommendation — a larger model will generally handle it better.
First-pass orchestration. If you are building a system where one model call sets the strategy for all downstream work, do not scrimp there. The cost of a few Sonnet calls to plan well is trivially small compared to the cost of a Haiku agent executing the wrong plan 10,000 times.
How Haiku 4.5 Compares to Other Fast Models
Claude Haiku 4.5 competes in the "fast, cheap, capable" tier alongside offerings from other AI labs. Rather than stating benchmark comparisons I cannot verify from Anthropic's official documentation, I will note the structural comparisons:
-
OpenAI GPT-4o mini / o4-mini: These are OpenAI's economy tiers. Anthropic positions Haiku 4.5 as having reached a similar capability ceiling to prior-generation Sonnet-level models. For tool-calling and computer-use, Haiku 4.5 has native Anthropic-designed support with the same reliability guarantees as the full model family.
-
Google Gemini Flash: Google's Flash tier is also a speed-optimized model for high-throughput tasks. Both operate in a similar price band; the right choice depends on your existing infrastructure, which tool-use formats you are already integrated with, and which model family your team has most experience prompting.
-
Open-weight models (Llama, Mistral, etc.): Self-hosted open-weight models can be cheaper at high volume for inference you control. The trade-off is operational overhead, lack of enterprise SLA, and the need to manage your own evaluation and safety posture. For most teams, managed API access to Haiku 4.5 is faster to ship and easier to audit.
If you are exploring the broader fast-model landscape, our post on Kimi K2 covers another strong contender in the efficiency tier, and our comparison of MiniMax M2 examines how Chinese AI labs are competing at the capable-but-cheap tier.
Availability: Where You Can Access Claude Haiku 4.5
Claude Haiku 4.5 is available through:
- Anthropic API — direct access via
claude-haiku-4-5-20251001as the model ID (orclaude-haiku-4-5as the alias per Anthropic's model docs). The model ID in Happycapy's system isanthropic/claude-haiku-4.5. - Amazon Bedrock — available as a managed service, serving as a drop-in replacement for Haiku 3.5 and Sonnet 4
- Google Cloud Vertex AI — available through the Vertex model garden
- Microsoft Azure AI Foundry — available via the Azure AI services layer
- Claude.ai free tier — Haiku 4.5 is accessible on the free tier of Claude.ai, making it available even to non-API users
For the full model reference and API parameters, see Anthropic's models documentation (note: docs.anthropic.com returns HTTP 403 to automated crawlers; the page is accessible via browser).
Happycapy and Claude Haiku 4.5
If you are building with Claude Haiku 4.5 in an agent loop, the fastest path from idea to running agent is often not managing API keys, configuring environments, and wiring tool execution yourself. That infrastructure is exactly what Happycapy handles.
On Happycapy, you select anthropic/claude-haiku-4.5 as your model and give your agent a task — file operations, web browsing, code execution, API calls — inside a secure cloud sandbox with no local setup required. More importantly, you can architect exactly the pattern described above: start with Haiku 4.5 for the fast sub-tasks, and switch a specific step to Sonnet or Opus mid-loop when you need more reasoning depth. With 150+ models available in the same interface, swapping is a dropdown selection, not a refactor.
Haiku 4.5's speed and low cost become most tangible when you can iterate quickly — testing prompts, watching the agent loop run, tuning the escalation logic — without paying Opus-tier prices for every experiment. That's the practical case for starting on Happycapy.
Frequently Asked Questions
What is Claude Haiku 4.5's context window?
Claude Haiku 4.5 supports a 200,000-token context window — the same as Claude Sonnet 4.5 and sufficient to process roughly 300 pages of dense text in a single request. Maximum output is 64,000 tokens. These figures are confirmed by Anthropic.
How does Claude Haiku 4.5 pricing compare to Sonnet?
As of mid-2026, Haiku 4.5 costs $1.00 per million input tokens and $5.00 per million output tokens. Sonnet 4.6 is reported at $3.00 input / $15.00 output per million tokens — three times more expensive on inputs. Always verify current pricing at anthropic.com/pricing.
Is Claude Haiku 4.5 good enough for coding tasks?
Yes, for the majority of software development sub-tasks. Anthropic reports Haiku 4.5 scored 73.3% on SWE-bench Verified — matching the coding performance Sonnet 4 achieved at its release. For complex architectural decisions, novel algorithm design, or highly ambiguous problem statements, Sonnet or Opus will outperform it. For code edits, test generation, documentation, and tool execution in a coding loop, Haiku 4.5 is typically sufficient.
What is "extended thinking" on Haiku 4.5?
Extended thinking allows the model to produce an internal chain-of-thought before emitting its final answer. This improves accuracy on tasks requiring step-by-step reasoning. Extended thinking was available on Sonnet and Opus in prior generations; Haiku 4.5 is the first Haiku-family model to support it. Note that thinking tokens are billed at output token rates ($5.00/million), so the cost benefit of Haiku versus Sonnet narrows when thinking is enabled.
Does Claude Haiku 4.5 support computer use?
Yes. Computer use — the capability to observe a screen and emit mouse/keyboard actions — was introduced to the Haiku family with version 4.5. This makes iterative browser and GUI automation practical at low cost, since each perception-and-action cycle is a separate model call.
When should I use Haiku 4.5 vs Sonnet 4.5 in an agent?
Use Haiku 4.5 for any sub-task that is: (a) short-context, (b) deterministic or verifiable, (c) highly repetitive, or (d) latency-sensitive. Use Sonnet 4.5 for planning, orchestration, tasks requiring nuanced judgment, or outputs where errors have significant downstream consequences. Many production systems use both: Sonnet plans, Haiku executes. See our context engineering for AI agents guide for patterns on structuring these flows.
How does Haiku 4.5 handle tool use?
Haiku 4.5 has full tool/function calling support, including structured outputs and JSON schema enforcement. It handles parallel tool calls and multi-turn tool execution. It is designed to be reliable in tight tool-call loops — the type of execution that powers computer-use and agentic coding.
Is Claude Haiku 4.5 available outside the Anthropic API?
Yes. Haiku 4.5 is available on Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Azure AI Foundry, in addition to the Anthropic API. On the consumer side, it powers features on the free tier of Claude.ai. For developers who want to run it without any API key setup, it is also available as a selectable model on platforms like Happycapy.
What is the knowledge cutoff for Claude Haiku 4.5?
Anthropic confirms the training knowledge cutoff as July 1, 2025. Events, publications, and developments after that date are not reflected in Haiku 4.5's base knowledge, though tool use (web search) can supplement this.
Summary
Claude Haiku 4.5 is not a toy or a fallback. It is a production-grade model that, as of its October 2025 release, performs at roughly the level of the prior generation's balanced tier — but at a fraction of the cost and several times the speed. Its natural home is inside agent loops: handling the fast, repetitive, tool-augmented steps that make up 80–90% of what an AI agent actually does in production, while handing off the rare genuinely hard decisions to a bigger model.
For teams building at scale — processing millions of documents, running thousands of agent turns per hour, or building interactive coding and customer-service tools — Haiku 4.5 is often the most economically rational default. The question is not whether it is "as smart as Opus," but whether it is smart enough for the specific task you need done, fast enough to feel real-time, and cheap enough to run at the volume your use case demands. For most agent sub-tasks, the answer is yes.
For a broader view of how fast models like Haiku 4.5 fit into the emerging landscape of capable, economical AI, see our coverage of Grok 4 and MiniMax M2 — two other models competing in the high-performance tier from different directions.

