
Context Engineering for AI Agents: A Practical Guide (2026)
What context engineering is, how it differs from prompt engineering, the four core techniques, how the major frameworks line up, how to measure it, and how to apply it in multi-agent systems.
An AI agent is only ever as good as the information sitting in its context window the moment it decides what to do next — and curating that information is the whole game. If prompt engineering is writing a good instruction, context engineering is managing the entire information environment the model works in: system instructions, tools, retrieved documents, memory, and the running history of the task. As agents take on longer, multi-step work, this has become the single biggest lever on whether they succeed or quietly fall apart. This guide covers what context engineering is, how it differs from prompt engineering, the core techniques, and how to apply it in real agent systems.
Why Context Engineering Matters
Context engineering matters because large language models have a finite context window, and how you fill that window determines the quality of every decision the agent makes. A model is only as good as the information in front of it — give it too little and it hallucinates; give it too much or the wrong kind, and its accuracy degrades.
This is not a theoretical concern. Researchers have documented a "lost in the middle" effect, where models reliably use information at the beginning and end of a long context but overlook facts buried in the middle. Practitioners describe a related problem they call "context rot": as a conversation or agent run grows longer, irrelevant tokens accumulate, the signal-to-noise ratio drops, and the model starts making worse choices. The window did not get smaller — it got cluttered.
The shift in terminology reflects a real shift in practice. In 2025, leading voices in AI — including Andrej Karpathy and Shopify's Tobi Lütke — argued that "context engineering" describes what people building serious LLM applications actually do far better than "prompt engineering" does. Anthropic published guidance on effective context engineering for agents; teams behind agent products like Manus wrote at length about the lessons they learned managing context in production. The consensus: for agentic systems, context is the product.
What Is Context Engineering?
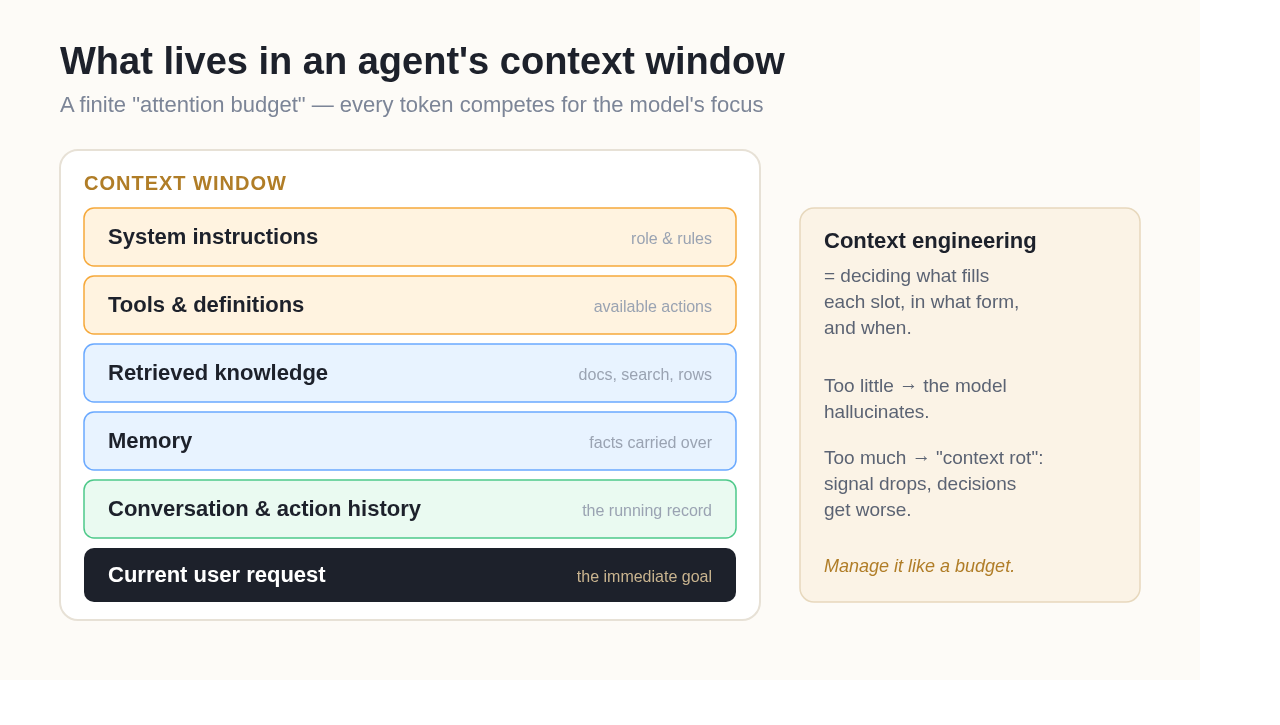
Context engineering is the discipline of assembling the right set of tokens for a model at inference time, so that the model has exactly what it needs to take the next correct action — no more, no less. The "context" includes everything inside the window:
- System instructions — the agent's role, constraints, and behavioral rules
- Tools and their definitions — what actions the agent can take, and how they're described
- Retrieved knowledge — documents, search results, or database rows pulled in for this task
- Memory — facts carried over from earlier in the session or from previous sessions
- Conversation and action history — the running record of what's been said and done
- The current user request — the immediate goal
Context engineering is the set of decisions about what goes into each of these slots, in what form, and when. It treats the context window as a scarce, managed resource rather than a bucket you keep pouring text into.
 The context window is a finite attention budget — context engineering decides what fills each slot.
The context window is a finite attention budget — context engineering decides what fills each slot.
Context Engineering vs Prompt Engineering
The difference between context engineering and prompt engineering is one of scope: prompt engineering optimizes a single instruction, while context engineering manages the entire, dynamic information environment across a multi-step task. Prompt engineering is a subset of context engineering.
| Prompt engineering | Context engineering | |
|---|---|---|
| Scope | One prompt / instruction | The whole context window over time |
| State | Mostly stateless, one-shot | Stateful, evolves across many steps |
| Concern | Phrasing, examples, formatting | What to include, retrieve, remember, and discard |
| Typical use | A single completion or chat turn | Autonomous agents, long-running tasks |
| Failure it prevents | A vague or misread instruction | Context rot, distraction, contradictory state |
Prompt engineering still matters — a well-phrased system prompt is part of good context engineering. But once an agent runs for dozens of steps, calls tools, and accumulates history, the wording of any single prompt is no longer the bottleneck. What matters is the discipline managing everything around it.
The Four Core Techniques
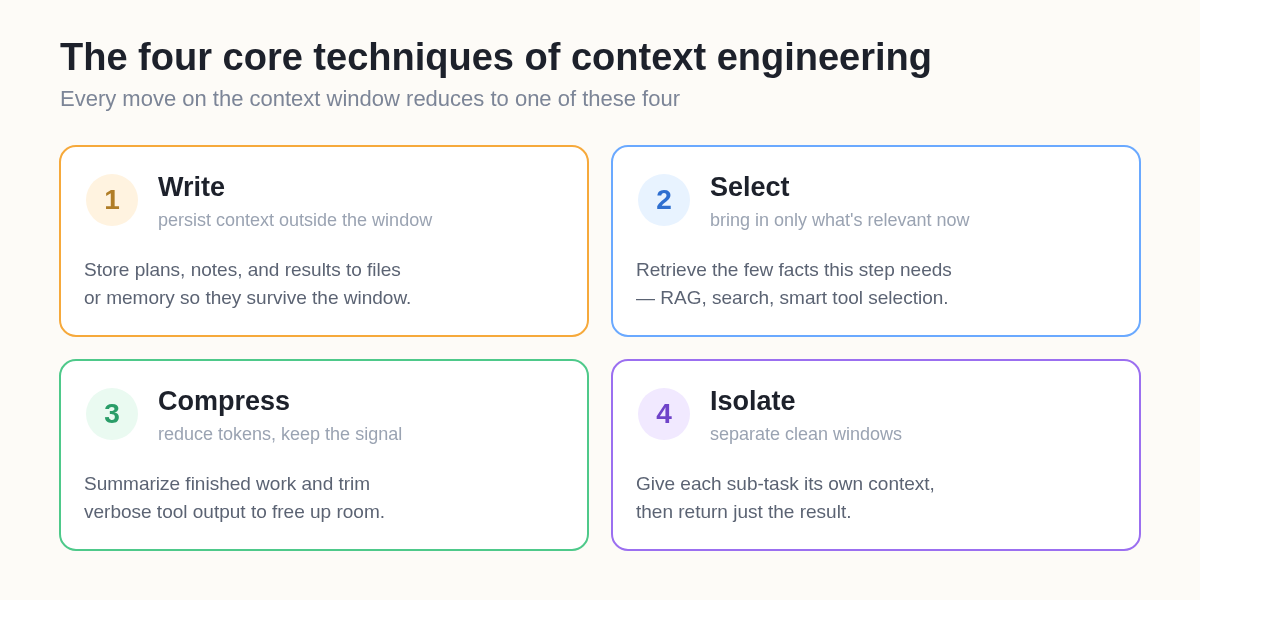
Most context engineering work reduces to four operations on the context window. A useful way to remember them: write, select, compress, and isolate.
 Write, select, compress, and isolate — the four operations behind every context engineering decision.
Write, select, compress, and isolate — the four operations behind every context engineering decision.
1. Write — persist context outside the window
Not everything the agent needs should live in the prompt. Writing context means storing information externally — scratchpads, files, a memory store, a task list — so it survives beyond a single window and can be recalled deliberately. A long-running agent that writes its plan to a file and re-reads it stays on track far better than one relying on the conversation history alone.
2. Select — bring in only what's relevant now
Selecting context is the art of retrieving the right information at the right moment: the specific document, the relevant past decision, the one tool definition this step needs. This is where retrieval-augmented generation (RAG), semantic search, and smart tool-selection live. The goal is precision — pulling the three relevant facts, not the three hundred adjacent ones.
3. Compress — reduce tokens while keeping signal
Compressing context means summarizing or pruning so the window holds meaning, not bulk. Common tactics include summarizing completed sub-tasks, truncating verbose tool outputs, and replacing long histories with a condensed recap. Compression is what lets an agent work on a task longer than its raw context window would otherwise allow.
4. Isolate — split context across agents or boundaries
Isolating context means giving different parts of a problem their own clean windows — for example, spawning a sub-agent with only the context it needs for one sub-task, then returning just the result. Isolation prevents one part of a job from polluting another and is the foundation of reliable multi-agent systems.
How the Leading Frameworks Line Up
One source of confusion is that every major team uses its own vocabulary for the same underlying operations. Anthropic, LangChain, and graph-database vendors like Neo4j all describe context engineering differently — but they map cleanly onto the four operations above. This table reconciles them:
| Operation (this guide) | Anthropic's framing | LangChain's framing | Knowledge-graph / GraphRAG framing |
|---|---|---|---|
| Write (persist outside the window) | Structured note-taking, agent memory (NOTES.md, to-do lists) | Store and State; tools that write via Command | Long-term memory; the graph itself as a persistent store |
| Select (retrieve what's relevant now) | Just-in-time context, agentic search, hybrid retrieval | Dynamic tool/message selection; tools that read | Hybrid RAG, GraphRAG, "minimum viable context" |
| Compress (reduce tokens, keep signal) | Compaction; spending the "attention budget" wisely | Life-cycle summarization via middleware | Token/cost budgeting; the "context pyramid" |
| Isolate (separate clean windows) | Sub-agent architectures returning distilled summaries | Lifecycle boundaries and sub-agents | Handoffs and protocols (e.g., MCP) |
If you've read those sources and felt they disagreed, this is why: they're describing the same four moves from different angles. Pick whichever vocabulary fits your stack — the operations are what matter.
Context Engineering for Multi-Agent Systems
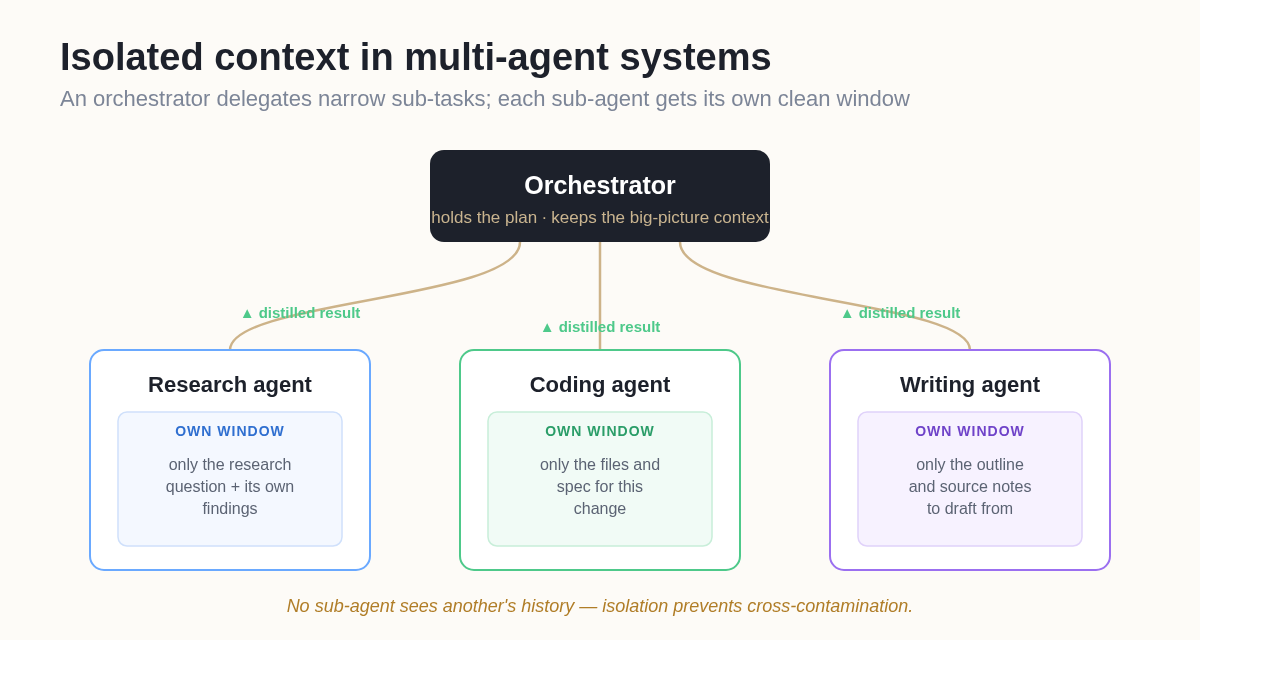
In multi-agent systems, context engineering becomes a coordination problem: each agent needs enough context to do its job, but sharing too much creates noise, cost, and contradictory state. The dominant pattern is an orchestrator that holds the high-level plan and delegates narrowly scoped sub-tasks to specialized sub-agents, each operating in an isolated window.
 Each sub-agent gets a clean, isolated window and returns only a distilled result — preventing cross-contamination.
Each sub-agent gets a clean, isolated window and returns only a distilled result — preventing cross-contamination.
This works because of the "isolate" principle above. A research sub-agent that only ever sees the research question and its own findings will outperform one that also has to wade through the unrelated history of a sibling agent's coding task. The orchestrator then compresses each sub-agent's output down to the essential result before folding it back into the main context. Done well, this is how teams run agents on tasks that would overflow any single context window many times over.
Common Context Engineering Failure Modes
Most agent failures trace back to a handful of recurring context problems. Naming them makes them easier to design against:
| Failure mode | What it looks like | Primary fix |
|---|---|---|
| Context poisoning | A hallucination or error enters the context and gets referenced again and again, compounding the mistake | Isolate + write verified facts only |
| Context distraction | The window grows so large the model over-focuses on accumulated history and stops reasoning about the actual goal | Compress |
| Context confusion | Irrelevant information crowds the window and misleads the model into a wrong choice | Select more narrowly |
| Context clash | Newly retrieved information contradicts what's already in the window, and the model can't reconcile the two | Select + write to a single source of truth |
The four core techniques are the antidotes: write to offload, select to stay relevant, compress to cut clutter, and isolate to prevent cross-contamination.
One failure mode the popular guides rarely cover is a security one: prompt injection through retrieved context. When an agent pulls in a web page, a document, or a tool result, that content can contain instructions designed to hijack the agent. Treat everything you select into the window as untrusted input — keep retrieved data separate from system instructions, and run tool execution in a sandbox rather than directly on a trusted machine.
How to Measure Whether Context Engineering Works
You measure context engineering by tracking task success against the tokens and time it takes to get there — good context engineering raises success rate while holding or lowering cost. Most guides describe techniques but never say how to know if they're working; these are the metrics that close that gap.
- Task success rate — the share of runs that reach a correct, complete result. This is the outcome metric; everything else is a means to it. Track it against a fixed evaluation set of representative tasks so you can compare before and after each change.
- Context efficiency (tokens per successful task) — total tokens consumed divided by successful completions. Falling token-per-success is the clearest signal that compression and selection are paying off.
- Window utilization — how full the context window runs during a task. Consistently near the limit predicts context rot; it's a leading indicator that you need to compress or isolate.
- Retrieval precision and recall — of the items you selected into the window, how many were actually relevant (precision), and of the relevant items available, how many you pulled in (recall). Poor precision means you're adding noise; poor recall means you're starving the model.
- Latency and cost per task — the practical ceiling. Aggressive "just-in-time" exploration can improve accuracy but slow the agent down; this metric keeps that trade-off honest.
The discipline that ties these together is regression testing: keep a suite of fixed tasks, run it after every change to prompts, retrieval, or memory, and watch the numbers move. Context engineering without an evaluation loop is guesswork.
How Happycapy Applies Context Engineering
Happycapy is an agent-native computer that runs AI agents — including Claude Code — directly in your browser, and context engineering is built into how those agents operate rather than left to the user. Three design choices do most of the work:
- Skills as scoped context. Instead of dumping every capability into one prompt, Happycapy lets an agent pull in a specific skill — design a deck, analyze a spreadsheet, do web research — so only the relevant instructions and tools enter the window for that task. That's the "select" and "isolate" principles applied by default.
- A persistent sandbox with memory and files. Each agent works in an isolated workspace where it can write plans, intermediate results, and notes to disk and recall them later — the "write" principle, so progress survives beyond a single context window.
- Access to 150+ models. Different steps have different context needs; routing work to an appropriate model is itself a context-engineering decision.
The practical upshot is that you can hand off a long, multi-step task and let the agent manage its own context in the background, then receive the finished result — without hand-tuning prompts or babysitting the window yourself.
Getting Started with Context Engineering
You don't need to rebuild your stack to start. Begin with the highest-leverage habits:
- Treat the context window as a budget. Before adding anything, ask whether it earns its tokens.
- Move state out of the prompt. Use files, scratchpads, or a memory store for anything the agent needs to keep.
- Retrieve narrowly. Pull the specific facts a step needs, not whole documents.
- Summarize as you go. Replace long histories and verbose tool outputs with tight recaps.
- Isolate sub-tasks. Give each distinct job its own clean context, especially in multi-agent setups.
If you'd rather not hand-tune any of this, Happycapy runs your tasks with these patterns already built into the agent: it manages its own context window in the background — selecting, compacting, and isolating as it goes — so you describe the outcome and never touch the token budget yourself.
Frequently Asked Questions
Q: Is context engineering the same as prompt engineering?
No. Prompt engineering optimizes a single instruction; context engineering manages the entire information environment an agent sees over a multi-step task — instructions, tools, retrieved data, memory, and history. Prompt engineering is one part of context engineering.
Q: Why is context engineering important for AI agents specifically?
Because agents run for many steps, call tools, and accumulate history, their context window fills up fast. Without active management, irrelevant tokens crowd out the signal and the agent's decisions degrade — a problem known as context rot. Context engineering keeps the window focused on what matters.
Q: What are the main context engineering techniques?
The four core techniques are write (persist context outside the window), select (retrieve only what's relevant now), compress (summarize to save tokens), and isolate (give sub-tasks their own clean context). Most practical work is some combination of these.
Q: Is context engineering a skill worth learning in 2026?
Yes. As more software is built on LLMs and autonomous agents, the ability to manage context well is becoming a core competency for developers, prompt designers, and AI product teams — and it's increasingly the difference between an agent that works and one that doesn't.
Q: How do you measure if context engineering is working?
Track task success rate against an evaluation set, plus efficiency metrics: tokens per successful task, context-window utilization, retrieval precision and recall, and latency/cost per task. Good context engineering increases success rate while holding or reducing cost. Run the suite after each change so you can see whether a tweak helped or hurt.
Q: Do I need to do context engineering myself to use AI agents?
Not necessarily. Agent platforms like Happycapy build context management into the system — scoping context with skills, persisting state in a sandbox, and isolating sub-tasks — so you can run multi-step work without tuning the context window manually.

