
MiniMax M2.7: The Open-Source Model Built for Agentic Workflows
MiniMax M2.7 is an open-source model tuned for agentic workflows and real software engineering. The verified facts, the benchmark numbers (with caveats), and how to run it with no setup.
MiniMax claims its M2.7 model is the highest-scoring open-source model on its headline benchmark — a bold thing to say about a model anyone can download and run. M2.7 is MiniMax's latest open-source release, built specifically for agentic workflows and real-world software engineering rather than chat. This guide separates the verified facts from the marketing, walks through the numbers (with the caveats they deserve), and shows the fastest way to actually put M2.7 to work.
What Is MiniMax M2.7?
MiniMax M2.7 is the latest text model in MiniMax's M-series, released as an open-source model — MiniMax positions it as the top open-source model on its headline benchmark, and it's distributed for others to use and build on. Where some models are pitched as general chatbots, M2.7 is explicitly aimed at getting work done: agentic workflows, end-to-end software projects, and even office-document tasks.
MiniMax highlights a concrete set of target use cases:
- Real-world software engineering — not snippets, but end-to-end project delivery.
- Log analysis and bug hunting, code security, and machine-learning tasks.
- Office Suite work — editing Excel, PowerPoint, and Word documents.
- Agentic workflows — operating as an autonomous, tool-using agent across multi-step tasks.
It ships in two flavors — standard MiniMax-M2.7 and M2.7-highspeed (MiniMax says identical results, just faster) — and it's designed to plug into the agent tooling developers already use, including Claude Code, Codex CLI, Cline, and Cursor.
The Numbers MiniMax Reports
M2.7 stands out partly because MiniMax published specific benchmark figures rather than vague claims. These are vendor-reported numbers — useful as a signal of where the model is strong, but always worth verifying on your own workload — and they paint a clear picture of an agentic, coding-focused model:
| Benchmark | MiniMax-reported result | What it measures |
|---|---|---|
| GDPval-AA | ELO 1495 — highest among open-source models | Broad real-world task value |
| SWE-Pro | 56.22% — "nearly matching Opus's best" | Real software-engineering tasks |
| VIBE-Pro | 55.6% | Coding/agentic capability |
| Terminal Bench 2 | 57.0% | Terminal/agent task completion |
| Skill adherence (40 complex skills, >2000 tokens) | 97% | Following multi-step instructions |
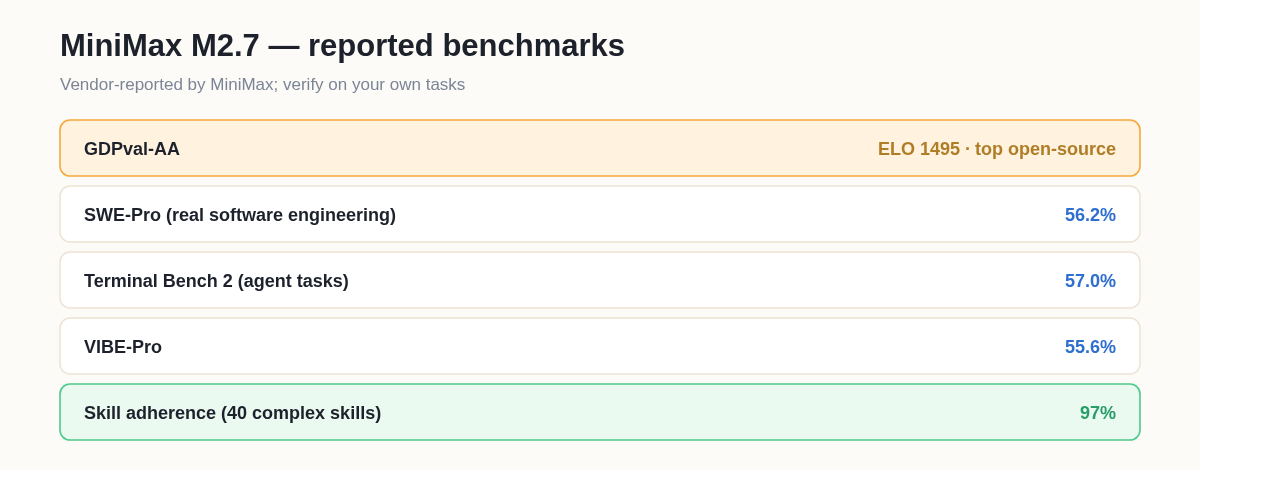 MiniMax's reported numbers for M2.7 — strong on software-engineering and agentic tasks (vendor-reported; verify on your own tasks).
MiniMax's reported numbers for M2.7 — strong on software-engineering and agentic tasks (vendor-reported; verify on your own tasks).
One claim deserves a specific flag: MiniMax frames the SWE-Pro score as "nearly matching Opus's best," but doesn't say which Opus version, so treat that particular comparison as marketing until it's independently verified. The honest read: even discounting for the fact that these are the maker's own benchmarks, the pattern is consistent — M2.7 is tuned for agentic and software-engineering work, and a 97% skill-adherence figure on long, complex instructions is exactly the trait that makes an agent reliable rather than flaky.
What MiniMax M2.7 Is Actually For
Put the benchmarks aside and the use case is clear: M2.7 is built to act, not just answer. The standout strengths line up with autonomous work — completing a software project end to end, hunting bugs through logs, editing real office documents, and following long multi-step skill chains without drifting. That last point matters most for agents: a model that holds a 97% skill-adherence rate across 40 complex skills is one you can trust to stay on task through a long job.
If your need is "draft me a paragraph," almost any model does it. If it's "work through this multi-step task and actually finish it," that's the lane M2.7 was built for.
How MiniMax M2.7 Stacks Up
A quick, honest placement against the models it's most often weighed against:
| If you want… | Consider |
|---|---|
| Open-source + agentic-workflow & office focus | MiniMax M2.7 |
| Open-source + coding/agent-swarm focus | Kimi K2.6 |
| A managed, closed coding agent | Claude (e.g. via Claude Code) |
| Maximum closed-frontier reasoning | A top GPT/Claude/Gemini-tier model |
M2.7 and Kimi K2.6 are the two open-source heavyweights in this conversation; M2.7 leans toward end-to-end agentic workflows and office tasks, while Kimi K2.6 leans toward coding and agent swarms. Both are worth testing on your actual work — which is much easier when you can run them side by side (more on that below).
Open Weights: Why It Matters for M2.7
M2.7 being open source isn't just a talking point — for an agentic, work-doing model it's genuinely useful:
- Run it where the work is. Self-host M2.7 next to your data and systems instead of routing sensitive code or documents through a third-party API — important for security-conscious teams handling real software or business files.
- Audit and adapt. Open weights can be inspected and fine-tuned for your domain, so the model can be shaped to your stack rather than taken as-is.
- No model-layer lock-in. You're not married to one vendor's endpoint; if a stronger open model lands, you can swap it in.
The catch is the same as with any open model: self-hosting a capable model means owning the GPUs and serving stack. So the practical question for most people isn't "open vs closed" — it's "do I run the ops myself, or use a managed host that already serves it?"
A Realistic M2.7 Workflow
Here's where M2.7's profile pays off. Say you hand it: "Audit this service's logs for the source of intermittent 500 errors, propose a fix, and draft a summary doc for the team." A model tuned for agentic workflows works through that as a sequence — pull and scan the logs, correlate the errors to a code path, propose and apply a fix, run a check, then generate a Word or PowerPoint summary of what it found and changed. That single task touches three of M2.7's stated strengths — log analysis/bug hunting, end-to-end software work, and Office-document output — which is exactly the kind of multi-step job its 97% skill-adherence score is meant to predict. A purely generative model would help with each piece if you prompted it five times; an agentic model like M2.7 is built to carry the whole chain.
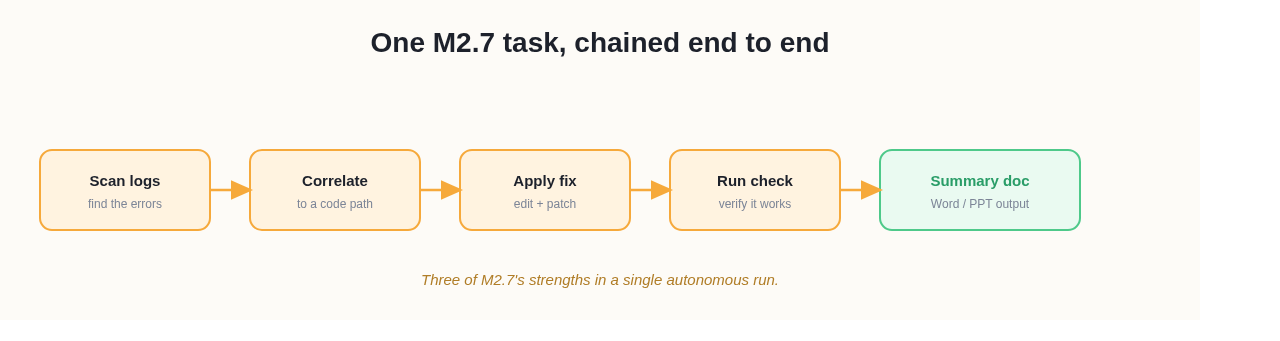 One M2.7 task, chained end to end — log analysis, a code fix, and a generated summary doc.
One M2.7 task, chained end to end — log analysis, a code fix, and a generated summary doc.
How to Run MiniMax M2.7
Three routes, from most hands-on to least:
- MiniMax's API — call it directly via MiniMax's endpoint (standard or highspeed), or wire it into agent tools like Claude Code, Cursor, or Codex CLI. Best if you're a developer comfortable managing keys.
- Self-host — because it's open source, you can run it on your own infrastructure for full control, at the cost of owning the setup and compute.
- A managed multi-model platform — use it through a service that already hosts it, with nothing to install. Lowest friction, and the right fit if you just want the model's output.
Run Your Whole Workflow in One Tab
Remember the workflow from earlier — scan the logs, trace the bug, apply a fix, then generate a summary doc? That entire chain runs end to end in Happycapy without you configuring a thing. M2.7 is one of the models you can pick in Happycapy, an agent-native computer in your browser, and it executes inside a cloud sandbox that already has the filesystem, terminal, and document tools that workflow needs — exactly the environment an agentic model requires to deliver, not just describe.
That's the real unlock for a model whose strength is finishing multi-step jobs: a benchmark score means nothing if the model has nowhere to act, and Happycapy gives it the place. You watch it work on a visual desktop and step in when you like. And because Happycapy also hosts Kimi K2.6, Claude, and 150+ other models, you can run your task on M2.7 and a rival in the same tab and keep the better result — no extra vendor accounts.
Start free at happycapy.ai, pick MiniMax M2.7, and hand it that exact kind of multi-step task — the fastest way to see whether its benchmark numbers hold up on your work.
The Honest Caveats
A clear-eyed view of M2.7 before you commit:
- The numbers are vendor-reported. MiniMax's benchmark figures are genuinely specific (which is good), but they're the maker's own. "Nearly matching Opus" and "top open-source" are claims to verify on your workload, not settled facts.
- Benchmark ≠ your work. A 57% on Terminal Bench or 56% on SWE-Pro tells you the model is competitive on those suites, not how it handles your codebase, your stack, and your conventions. The fifteen-minute test on a real task of yours is worth more than any score.
- It needs a harness to act. M2.7's headline is agentic workflows — but an agentic model is only as useful as the loop, tools, and sandbox around it. On its own it's a capable model; to actually deliver end-to-end work it needs an environment that lets it act.
- Open at the model layer, ops on you if self-hosting. Open weights give control, but serving a model of this class yourself is real infrastructure work. The managed path trades that away.
- Not automatically the top closed-frontier model. For the absolute ceiling on general reasoning, the leading closed models still set the bar; M2.7's case is open-source agentic strength, not "beats everything."
Go in expecting a strong open agentic model — and confirm the parts that matter to you on your own tasks.
Who Should Use MiniMax M2.7?
- Builders of agentic workflows who want an open-source model proven on multi-step, tool-using tasks.
- Developers doing real software engineering who want strong SWE performance without a closed-only model.
- Teams that need open source for control, self-hosting, or avoiding lock-in.
- Anyone choosing between open models who wants to benchmark M2.7 against Kimi K2.6 on their own tasks.
Frequently Asked Questions
Q: Is MiniMax M2.7 open source?
Yes — MiniMax released M2.7 as an open-source model and reports it as the highest-scoring open-source model on the GDPval-AA benchmark. That means you can use and self-host it, not just call a closed API.
Q: What is MiniMax M2.7 best at?
Agentic workflows and real-world software engineering — end-to-end project delivery, bug hunting through logs, code security, ML tasks, and even Office-document editing. It's tuned to complete multi-step work, not just answer questions.
Q: How good is MiniMax M2.7, really?
MiniMax reports strong numbers — an ELO of 1495 on GDPval-AA (top open-source), 56.22% on SWE-Pro, 57.0% on Terminal Bench 2, and 97% skill adherence on complex instructions. These are vendor-reported, so treat them as a strong signal of its focus and verify on your own tasks.
Q: What's the difference between MiniMax-M2.7 and M2.7-highspeed?
MiniMax describes them as producing identical results, with the highspeed variant simply running faster (and offering automatic cache support). Pick highspeed when latency matters.
Q: How can I use MiniMax M2.7 without setup?
Run it in Happycapy, which provides M2.7 inside a ready cloud sandbox — filesystem, terminal, and document tools included. You pick it in the browser and hand it a multi-step task; the environment it needs to complete the work is already there, so there's nothing to install or key-manage.
Q: Does MiniMax M2.7 work with coding tools like Cursor and Claude Code?
Yes — MiniMax lists M2.7 as compatible with a range of agent tools including Claude Code, Codex CLI, Cline, and Cursor, so you can plug it into the workflow you already use. Or run it through a managed platform if you'd rather skip the setup entirely.
Q: Is MiniMax M2.7 free to use?
The weights are open, so self-hosting carries no license fee (you pay for compute), and MiniMax offers a token-based plan for its API. Managed platforms bundle access into their own pricing — for example, you can run M2.7 in Happycapy alongside 150+ other models without a separate MiniMax account.
Q: MiniMax M2.7 vs Kimi K2.6 — which should I pick?
Both are leading open-source agentic models. M2.7 leans toward end-to-end agentic workflows and office tasks; Kimi K2.6 leans toward coding and agent swarms. The reliable way to choose is to run the same task through both — easy on a platform that hosts both, like Happycapy.

