
Claude Fable 5: Anthropic's Most Powerful — and Most Controversial — Model, Explained
Anthropic's top Mythos-class flagship — not a storytelling model — and the first commercial AI model pulled by a government order.
Claude Fable 5: Anthropic's Most Powerful — and Most Controversial — Model, Explained
Claude Fable 5 is not a creative-writing model. It is not a storytelling assistant. It is Anthropic's new flagship frontier model — the most capable system the company has ever released publicly — and it has already been pulled from the market by a US government order, and brought back. The name is a distraction. The model is a seismic event.
That confusion is the first thing to clear up. Search for "Claude Fable 5" and you will find breathless guesses that "Fable" signals some kind of literary or narrative specialization. It does not. The Fable product line is simply Anthropic's public-release branding for its new Mythos-class architecture — a tier that sits above Opus, Sonnet, and Haiku, all of which you can now think of as generation-4 or transitional names. Claude Fable 5 is Anthropic's version of what competitors call their "frontier" or "ultra" tier: maximum reasoning depth, maximum context, maximum agentic reach. The name was chosen for its mythology connotations, not its storytelling ones.
Now that we have that out of the way — let us talk about what actually happened between June 9 and July 1, 2026. Because this model's launch is the most unusual commercial AI release in history, and that story tells you almost everything you need to know about where the industry is heading.
What Happened: A Three-Week Suspension That Changed Everything
Claude Fable 5 launched on June 9, 2026. Within 72 hours, developer communities were posting early evals. The numbers were striking even compared to Opus 4.8: SWE-bench Verified at 95.0%, Terminal-Bench at 88.0%, Humanity's Last Exam without tools at 59.0%. Early enterprise testers and developer communities widely praised its long-horizon coding and analytics performance — several described working with it as less like using an assistant and more like commissioning a small team. The reception was, by any measure, exceptional.
Then, on June 12 — three days after launch — Anthropic suspended the model's availability across all commercial channels. The reason was not a safety incident in the conventional sense. It was a US government export-control order: the first time in modern commercial AI history that a released, production model has been pulled from the market by regulatory action. Not withdrawn voluntarily for safety review. Not quietly deprecated. Suspended — by order — for export compliance reasons.
The specifics of what triggered the order have not been made fully public. What is known is that the order covered cross-border API access to the model's full capabilities and specifically cited concerns about the dual-use implications of Fable 5's agentic and long-context reasoning features at scale. The suspension lasted 19 days. Anthropic redeployed the model on July 1, 2026, with additional access-tier controls and geographic restrictions added to the API.
The implications are significant. We now live in a world where a commercial AI model — not a weapons system, not classified research, but a publicly sold text-and-vision API — can be suspended by government order mid-deployment. That is new. It will not be the last time it happens.
 Timeline: Claude Fable 5 launched June 9, was suspended June 12 by US export-control order — the first such action against a commercial AI model — and redeployed July 1 with additional access controls.
Timeline: Claude Fable 5 launched June 9, was suspended June 12 by US export-control order — the first such action against a commercial AI model — and redeployed July 1 with additional access controls.
Mythos vs. Fable: The Architecture Behind the Name
Understanding Claude Fable 5 requires understanding the Mythos-class distinction, because the two names refer to the same weights with different safety layers applied.
Claude Mythos 5 is the base architecture. It has classifiers removed or reduced in certain domains and is available only to vetted partners through a restricted program called Project Glasswing. You cannot buy Mythos 5 on the standard API. It is a research and enterprise-restricted tier.
Claude Fable 5 is Mythos 5 with Anthropic's full production safety classifier stack applied on top. This is the version available on the Claude API, AWS Bedrock, Google Vertex, Azure Foundry, and claude.ai. The underlying reasoning capabilities are identical. The behavioral envelope is shaped by classifiers.
When benchmark tables show Fable/Mythos numbers, they frequently merge the higher score from either variant into a single row. That is important context: the published 95.0% SWE-bench Verified number may reflect Mythos performance in a classifier-off configuration, not the Fable 5 you actually get when you call claude-fable-5 in the API. Anthropic uses its own scaffold rather than Scale SEAL for these evals, adding another layer of uncertainty. The honest read is that Fable 5 is substantially better than Opus 4.8 — but the exact delta on any individual benchmark is harder to pin down than the published table suggests.
What is not ambiguous: the architectural specs.
| Feature | Claude Fable 5 | Claude Opus 4.8 |
|---|---|---|
| Context window | 1,000,000 tokens | 200,000 tokens |
| Max output | 128,000 tokens | 32,000 tokens |
| Input pricing | $10 / M tokens | $15 / M tokens |
| Output pricing | $50 / M tokens | $75 / M tokens |
| Batch input | ~$5 / M | ~$7.50 / M |
| Cache hit (input) | ~$1 / M | ~$1.50 / M |
| Modalities | Text + vision | Text + vision |
| Adaptive thinking | Always on | Optional |
| Chain-of-thought exposed | No | No |
| API identifier | claude-fable-5 | claude-opus-4-8 |
Two things Anthropic has not published for Fable 5: a training-data knowledge cutoff and a parameter count. Neither figure should be stated or inferred, and you should be skeptical of any third-party source that claims a specific number.
The 1M-token context is the headline spec and it is genuinely useful — whole codebases, lengthy contract sets, large document corpora. The 128k output ceiling means the model can produce substantially longer artifacts in a single pass than Opus. Adaptive thinking is always on in Fable 5, which means the model automatically decides how much reasoning budget to allocate per query; you cannot force it into fast-shallow mode, but you also cannot inspect the chain of thought it produces internally.
The Safety Fallback: A Genuinely Novel — and Genuinely Controversial — Design
Fable 5's most distinctive production behavior is not a capability. It is a constraint mechanism that no prior production model has deployed at this scale.
When Fable 5's classifiers detect a request falling into certain high-risk categories — specifically, cybersecurity attack tooling, biological agent synthesis, chemical weapons–adjacent queries, and attempts to distill or clone the model's weights — the request is not refused. It is silently rerouted to Claude Opus 4.8, which responds instead. The user receives an Opus response with a brief notification that the request was handled by a different model variant. Less than 5% of sessions trigger this mechanism.
This is clever in theory. Hard refusals train adversaries to craft around them. A graceful degradation to a capable-but-different model disrupts the distillation signal while still serving legitimate edge cases. The user is not left with a blunt "I cannot help with that."
In practice, it has generated significant criticism from researchers who have legitimate professional needs in exactly the domains the classifier targets. Security researchers building red-team tooling. Biologists studying pathogen defense. Chemists working in regulatory contexts. For these users, an opaque "shadow-ban" that silently downgrades their request without explaining which aspect triggered the classifier is operationally disruptive. You do not know whether you hit the ceiling because of a phrase choice, a document you attached, or a persistent context from earlier in the session. You get an Opus answer and a terse note.
Anthropic's position is that the classifier is intentionally opaque to prevent adversarial probing. That is coherent. It is also not a satisfying answer for a professional who needs to know whether their workflow is structurally incompatible with Fable 5 or whether a minor prompt adjustment would resolve it.
The design is genuinely novel. The tradeoffs are genuinely real. Both things are true.
For most Happycapy users building agentic workflows — coding agents, data analysis agents, document processing pipelines — none of this applies. The sub-5% trigger rate means the overwhelming majority of production use cases never encounter the fallback at all. But if your work touches the flagged domains, you need to know this mechanism exists before you build on Fable 5.
Who Should Actually Pay $50 Per Million Output Tokens
This is where most coverage stops being useful. The benchmark numbers are impressive. But should you be using Fable 5?
The honest answer for most developers: probably not as your default model. Here is the breakdown.
Use Fable 5 when:
- Your task requires processing context larger than 200k tokens — whole repositories, regulatory document sets, multi-session memory consolidation.
- You are running a long-horizon agentic workflow where the model needs to plan, execute, and recover from failures across many steps without human check-ins. The harness engineering guide on this blog covers why this matters architecturally.
- The output itself is the deliverable and length/quality justify the cost — a deep technical report, a comprehensive codebase refactor, an enterprise-grade spec document.
- You are building a coding agent that needs to stay on hard problems. The best AI agent for coding comparison shows why model ceiling matters in agentic loops.
- You are doing multimodal analysis on complex visual inputs where SWE-bench-level reasoning is required to interpret the content, not just describe it.
Do not use Fable 5 when:
- You are doing high-volume, routine inference. At $50/M output, a chatbot handling 500 daily sessions at average 1,000 output tokens each costs $25/day — $750/month — just on output. Sonnet or Haiku handles most of that workload at a fraction of the cost.
- Your task fits in 200k context and does not require Fable-level reasoning depth. Most of it does not.
- You are prototyping. Use the cheaper tiers to validate your pipeline, then upgrade the model when you know the architecture works.
- You are comparing models. The Claude Haiku 4.5 overview is a useful reference point for understanding how much headroom Anthropic's lighter models actually have for mid-complexity tasks.
The $10/M input pricing is actually lower than Opus 4.8 ($15/M), which makes Fable 5 competitive for read-heavy workloads against long documents. The expensive side is output. If your use case generates short answers against long contexts — classification, extraction, structured output — Fable 5 is not as expensive as the sticker price implies. If your use case generates long outputs, the math gets punishing fast.
Where to Run It
Claude Fable 5 is available on every major platform:
- Anthropic API —
claude-fable-5, with the standard claude.ai interface for interactive use - AWS Bedrock — model ID
anthropic.claude-fable-5 - Google Vertex AI and Azure AI Foundry — through standard provider integration
- Claude Code — Anthropic's agentic coding CLI, now using Fable 5 as its top tier
- OpenRouter and Cloudflare Workers AI — for developers routing across providers
- Happycapy — part of the 150+ model catalog, accessible in browser with full tool support including code execution, file handling, and MCP integrations
If you want to compare Fable 5 against Opus 4.8, Sonnet, GPT-5.5, Gemini Ultra, or any other model in the same session, Happycapy is genuinely the fastest path to that comparison. You can run all of them side-by-side in a cloud sandbox without provisioning API keys for each provider. Start free at happycapy.ai — the multi-model comparison view is available on the free tier.
The agentic use case is where Happycapy's architecture becomes especially relevant for Fable 5. Fable 5's 1M-token context and long-horizon planning capabilities are most valuable when paired with real tools — file systems, code execution, web access. Running a Fable 5 agent in a sandboxed environment with those tools available is exactly what the platform is built for. The agentic AI vs AI agents explainer covers why this distinction matters when you are deciding how to architect a Fable 5 workflow.
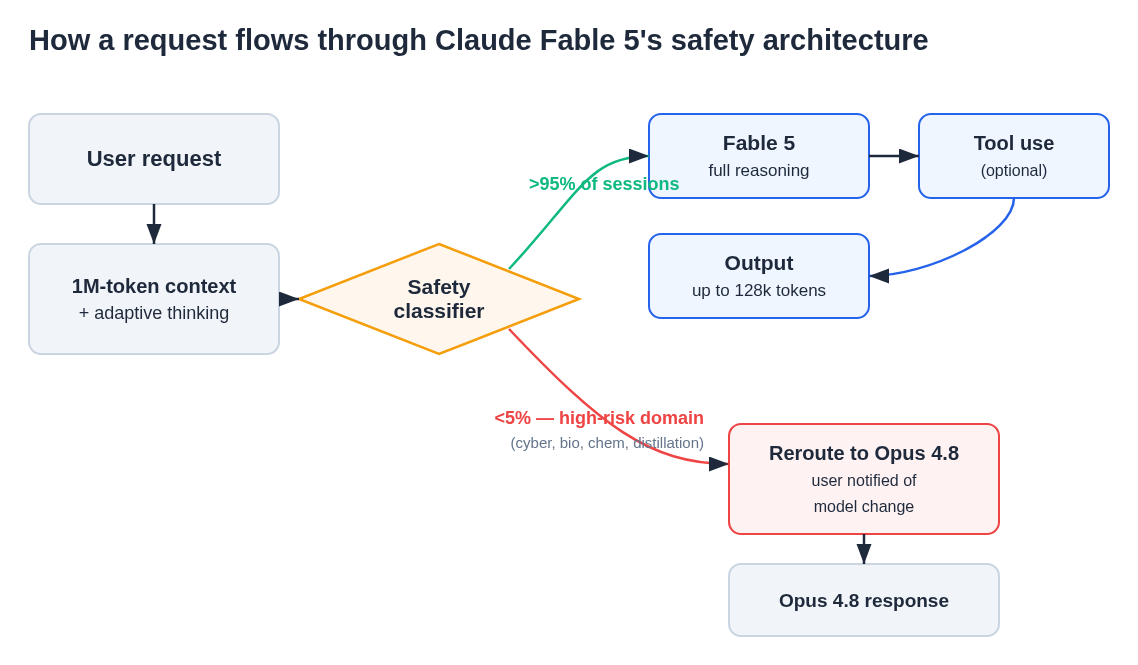 Fable 5's production architecture: 1M-token context with adaptive thinking feeds into the safety classifier layer. High-risk requests are rerouted to Opus 4.8 with notification; standard requests proceed through Fable 5's full reasoning stack to tool use and output.
Fable 5's production architecture: 1M-token context with adaptive thinking feeds into the safety classifier layer. High-risk requests are rerouted to Opus 4.8 with notification; standard requests proceed through Fable 5's full reasoning stack to tool use and output.
The Benchmark Caveat Nobody Mentions
Let us be specific about the numbers that have been circulating, because the way they are presented invites overconfidence. Here is the headline table Anthropic published, before the caveats:
| Benchmark | Fable 5 | Opus 4.8 | GPT-5.5 |
|---|---|---|---|
| SWE-bench Verified | 95.0% | 88.6% | — |
| SWE-bench Pro | 80.3% | 69.2% | 58.6% |
| FrontierCode Diamond | 29.3% | 13.4% | 5.7% |
| Terminal-Bench 2.1 | 88.0% | 82.7% | — |
| GDPval-AA (Elo) | 1932 | 1890 | — |
| OSWorld-Verified | 85.0% | 83.4% | — |
| HealthBench Professional | 66.0% | 56.9% | — |
| Humanity's Last Exam (no tools / with tools) | 59.0% / 64.5% | 49.8% / 57.9% | — |
Now the caveats, because they matter more than the numbers.
SWE-bench Verified at 95.0% is near the saturation ceiling of the benchmark. At that level, the benchmark is measuring the difficulty of the remaining 5% more than it is differentiating models. SWE-bench Pro — the harder variant — is the more useful signal, and Fable/Mythos at 80.3% versus Opus 4.8 at 69.2% represents a meaningful gap. But 80.3% Pro also means one in five real-world software engineering tasks fails, which is a different frame than "best ever."
Terminal-Bench 2.1 at 88.0% comes with a notable asterisk: approximately 20.9% of trials in the Terminal-Bench suite triggered a safety refusal that prevented task completion. Those trials counted against Fable 5's score, not against a competitor that would have completed them without refusal. The headline number thus underrepresents raw capability while also being genuinely the production behavior you will get.
Humanity's Last Exam — 59.0% without tools, 64.5% with tools — is an impressive frontier result on a benchmark designed to be hard. But HLE spans domains from mathematics to classics to biology, and performance is highly uneven across them. A 59% average does not mean 59% success on any given expert question.
The overall picture is that Fable 5 is a real, substantial step forward from Opus 4.8. The specific numbers in the published table are best treated as directional indicators rather than precise measurements of what you will see in production. The TechCrunch coverage at launch noted the broader context: Anthropic itself had recently published warnings about AI development pace, which made the simultaneous release of its most powerful model a notable tension worth sitting with.
The Bigger Picture: Government Control of AI Infrastructure
The June 12 suspension deserves more than a footnote. It is the event that will be cited in future histories of AI governance as the first concrete example of state-level intervention in commercial model availability.
The order itself remains partially opaque in its specifics. What is clear is that a US government agency determined that the cross-border availability of a commercial text-and-vision model posed sufficient export-control risk to warrant suspension of its deployment. The model was not modified during the 19-day suspension. The redeployment on July 1 came with additional geographic access controls — meaning certain API calls are now filtered by origin country in ways that were not present on June 9.
This is not a hypothetical future in which governments regulate AI. It is the present. The suspension affected developers who had already integrated Fable 5 into production workflows. It affected enterprises that had deployed it on Bedrock. It affected researchers running evals. Nineteen days of absence in a production system is not trivial.
What does this mean for builders? It means that even a model from the world's most compliance-oriented AI lab can vanish from the API on three days' notice. If you are building on Fable 5 — or any frontier model — multi-provider fallback architecture is no longer paranoia. It is engineering hygiene. The MCP server guide touches on how tool-call infrastructure can be designed for provider portability; the same principles apply to the model layer.
Anthropic handled the suspension with relative transparency — they communicated quickly and redeployed within three weeks. That is better than the alternative. But the incident reveals that the availability of any given model is not simply a commercial decision between Anthropic and its customers. It is a decision in which government actors now have demonstrated willingness to intervene.
FAQ
What is Claude Fable 5?
Claude Fable 5 is Anthropic's current flagship frontier model, sitting above Opus, Sonnet, and Haiku in the capability hierarchy. It is based on the Mythos-class architecture and was publicly released on June 9, 2026. It is a general-purpose reasoning and long-horizon agentic model with a 1M-token context window and text + vision capabilities. API identifier: claude-fable-5.
Is Claude Fable 5 a creative writing or storytelling model? No. The "Fable" name is a product-line branding choice with no functional relationship to creative writing. Claude Fable 5 is a general-purpose frontier model optimized for reasoning, coding, analysis, and long-horizon agentic tasks. It is the most capable model Anthropic has released publicly, not a specialized creative assistant.
How does Claude Fable 5 compare to Opus 4.8? Fable 5 outperforms Opus 4.8 across the major benchmarks: SWE-bench Verified 95.0% vs 88.6%, SWE-bench Pro 80.3% vs 69.2%, Terminal-Bench 88.0% vs lower. Fable 5 also has 5x more context (1M vs 200k tokens) and 4x higher max output (128k vs 32k). However, Fable 5's output pricing ($50/M) is the primary constraint for high-volume use cases; Opus 4.8 at $75/M output is actually more expensive, making Fable 5 the better deal if you need this capability tier. Most routine use cases do not need either — Sonnet or Haiku is sufficient.
What is Claude Fable 5 pricing? Standard API: $10 per million input tokens, $50 per million output tokens. Batch mode: approximately $5/$25. Cache hits on input: approximately $1/M. Pricing is broadly comparable to Opus 4.8 (which was $15/$75) and represents a price reduction at this capability tier.
Why was Claude Fable 5 suspended? Fable 5 was suspended on June 12, 2026 — three days after launch — by a US government export-control order. This was the first time a commercial AI model had been pulled from the market by regulatory action rather than a voluntary safety withdrawal. The model was redeployed on July 1, 2026 with additional geographic access controls. Anthropic has not published the full specifics of the order.
What is the difference between Claude Fable 5 and Claude Mythos 5? Same underlying weights, different safety layers. Mythos 5 has classifiers reduced or removed in certain high-risk domains and is restricted to vetted partners through Project Glasswing. Fable 5 is Mythos 5 with Anthropic's full production safety classifier stack applied. Published benchmark tables sometimes merge the higher score from either variant, which can make Fable 5's standalone performance harder to assess precisely.
What is the Opus fallback in Claude Fable 5? When Fable 5's classifiers detect high-risk requests in cybersecurity, biological, chemical, or model-distillation domains, the request is silently rerouted to Claude Opus 4.8, which responds instead, with a brief user notification. Less than 5% of sessions trigger this. Critics — particularly security researchers and biologists with legitimate professional needs — have called the opaque, non-explanatory fallback a "shadow-ban" that disrupts professional workflows without sufficient transparency.
Try It Without Commitment
If you want to run Claude Fable 5 alongside Opus 4.8, Sonnet, GPT-5.5, or any of 150+ other models to see where the real-world performance gap actually shows up in your specific use case, Happycapy gives you that in a browser with no setup required. You bring the task. The platform brings the infrastructure.
The model is back. The story behind why it disappeared — and what that means for the industry — is not going away.

