
Loop Engineering for AI Agents: The 2026 Guide
Loop engineering is the cycle behind every reliable AI agent. Learn what an agentic loop is, loop vs chain, the core patterns, failure modes and guardrails, and how to measure a loop.
Behind every reliable AI coding agent is a loop — the cycle of act, observe the result, decide what to do next, and repeat until the goal is actually met. Designing that cycle well is what loop engineering means, and a growing consensus holds that what separates a great agent from a mediocre one usually isn't the underlying model, it's the loop. This guide explains what an agentic loop is, how it differs from a chain, the common loop patterns, the failure modes to guard against, and how to measure whether your loop actually works.
Why AI Agents Need Loops
AI agents need loops because real tasks aren't one-shot — they require trying something, seeing what happened, and adjusting. A single prompt-and-response can answer a question, but it can't fix a failing test, refactor a module, or complete a multi-step job where step three depends on what step two returned. The loop is what turns a language model into something that can make progress.
This is why two agents built on the same model can perform completely differently. Identical intelligence, different loop design: one gives up or spins in circles, the other detects the failure, revises its plan, and finishes. Loop engineering is the work that makes the difference.
What Is an Agentic Loop?
An agentic loop is a cycle in which an agent reasons about a goal, takes an action, observes the outcome, and decides whether to continue or stop. Most loops share the same internal stages — commonly summarized as reason → act → observe — wrapped in a check against the goal that decides whether to iterate again.
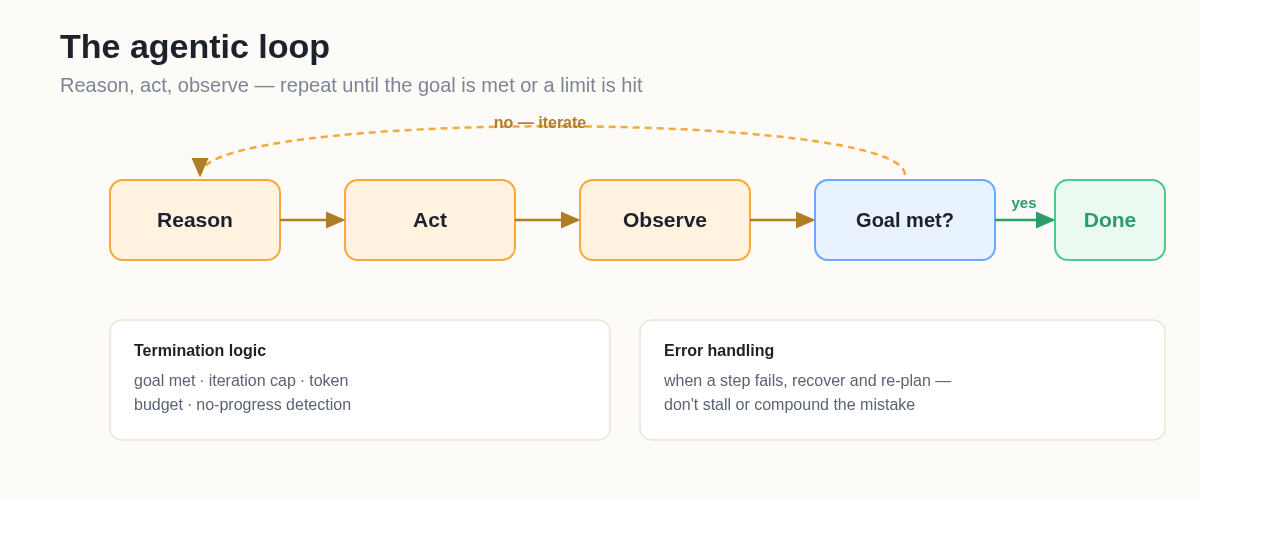 The agentic loop: reason, act, observe — repeat until the goal is met or a limit is hit.
The agentic loop: reason, act, observe — repeat until the goal is met or a limit is hit.
The pattern traces back to ReAct (Reason + Act), which interleaved a model's reasoning with tool calls, and has since evolved through ideas like Reflexion (self-critique), plan-and-execute, and the long-running "while not done" loops used by modern coding agents.
Loop vs Chain: The Key Distinction
A chain is linear and fixed (A → B → C), while a loop is cyclic and revisable — it can repeat, branch, or change course based on what it observes. This is the single most useful distinction in loop engineering.
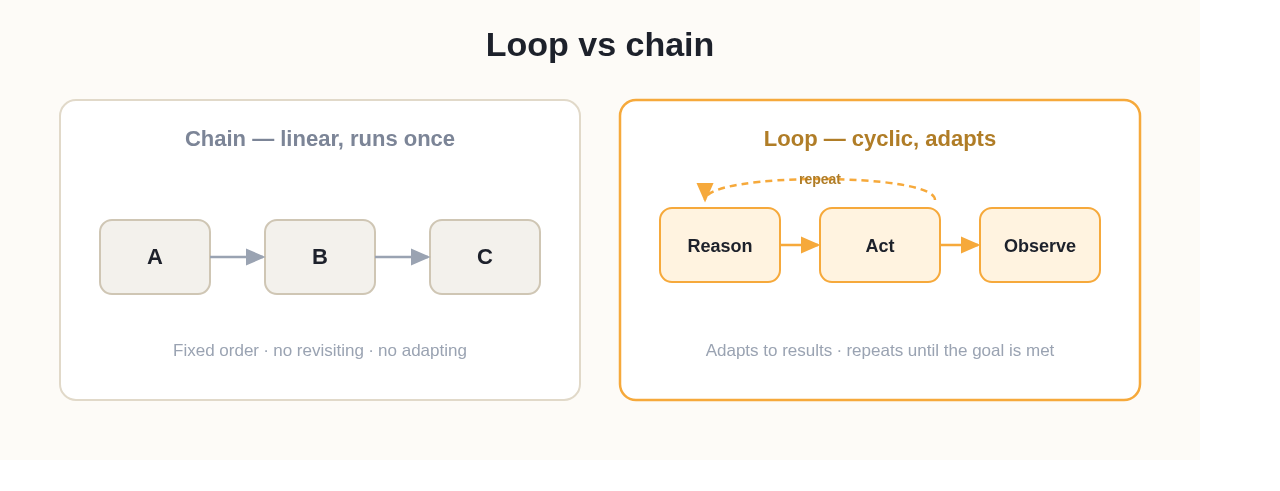 A chain runs once in a fixed order; a loop adapts and repeats until the goal is reached.
A chain runs once in a fixed order; a loop adapts and repeats until the goal is reached.
A chain is great when the steps are known in advance and never need to change. A loop is necessary when the path can't be fully planned upfront — which is almost always true for agentic work like coding, research, or debugging.
The Anatomy of a Well-Engineered Loop
Most reliable loops are built from the same five parts. Get these right and the loop holds together; neglect one and it fails in a predictable way.
- Goal definition — a clear, ideally verifiable objective the loop is working toward (tests pass, file produced, question answered). A loop with a fuzzy goal never knows when to stop.
- Tools / actions — what the agent can actually do each iteration (run a command, edit a file, search the web).
- Observation — how the result of each action is fed back in, ideally as structured feedback rather than raw dumps.
- Termination logic — the conditions that end the loop: goal met, iteration cap reached, token budget spent, or no progress detected.
- Error handling — what happens when a step fails, so the loop recovers instead of stalling or compounding the mistake.
Common Loop Patterns
Different jobs call for different loop shapes. These are the patterns worth knowing, roughly in order of sophistication:
| Pattern | How it works | Best for |
|---|---|---|
| Retry loop | Repeat an action until it succeeds or a limit is hit | Flaky steps, transient failures |
| Plan-execute-verify | Plan steps, execute them, then verify the result against the goal | Multi-step tasks with a checkable outcome |
| Explore-narrow | Gather broadly, then converge on the best path | Research and discovery |
| Reflexion (self-critique) | After acting, the agent critiques its own output and retries | Quality-sensitive work |
| Human-in-the-loop | Pause for human approval at key points | High-stakes or irreversible actions |
| Multi-agent orchestration | An orchestrator runs sub-loops in specialized sub-agents | Large jobs that exceed one agent's scope |
The trend across 2026's most capable coding agents is toward longer-running, self-verifying "while-not-done" loops with strong termination logic and parallel sub-loops handled by sub-agents.
Failure Modes and the Guardrails That Fix Them
Most loop failures are well-known, and each has a standard guardrail. Design for these from the start:
| Failure mode | What it looks like | Guardrail |
|---|---|---|
| Infinite loop | The agent never decides it's done | Iteration cap + no-progress detection |
| Goal drift | It wanders off the original objective | A clear, re-checked goal each iteration |
| Context overflow | The window fills with history and quality drops | Context engineering: compaction and summarization |
| Token explosion | Cost spirals as the loop runs | Token budget as a termination condition |
| Error propagation | One bad step poisons every step after it | Robust error handling + verification |
| Prompt injection | Malicious instructions in observed content hijack the loop | Treat tool/web output as untrusted; run in a sandbox |
That last one — prompt injection through the content the loop observes — is rarely covered in loop-engineering guides but matters as much as the rest: every web page or file the agent reads is untrusted input, so a loop that takes real actions should run inside an isolated sandbox.
How to Measure Whether a Loop Works
You measure a loop by whether it reaches the goal reliably, in how many iterations, and at what cost. Most write-ups describe patterns but never say how to evaluate one — these are the metrics that matter:
- Goal success rate — how often the loop reaches a correct, complete result. The headline metric.
- Iterations to goal — how many cycles it takes on average. Fewer (for the same success) means a tighter loop.
- No-progress rate — how often the loop runs without moving closer to the goal, a leading indicator of drift or a bad termination condition.
- Cost and tokens per goal — the practical ceiling; single-agent loops are token-heavy and multi-agent loops more so, so this keeps the design honest.
- Recovery rate — when a step fails, how often the loop self-corrects instead of stalling.
Run these against a fixed set of representative tasks and re-check after every change to the loop. The trap to avoid: a loop that "feels" smarter but quietly takes more iterations (and tokens) to reach the same goal is a regression, not an upgrade — only the numbers will tell you.
How Loop Engineering Fits With Context and Harness Engineering
Loop engineering is one layer of building a reliable agent, alongside two others. The loop is the cycle; context engineering decides what the agent sees on each pass of that cycle; and harness engineering is the whole system — loop, context management, tools, memory, and sandbox — wrapped around the model. A great loop with poor context management still fails, which is why these disciplines are best learned together.
You don't have to build this machinery yourself. On Happycapy the loop runs for you in a sandbox — iteration limits, error recovery, and context compaction already wired in — and you watch each pass of the cycle on a visual desktop, stepping in mid-loop whenever you want to redirect it before it burns another iteration.
Frequently Asked Questions
Q: What makes an agentic loop reliable?
Five parts working together: a clear, verifiable goal; the right tools; structured observation of each result; termination logic (iteration cap, token budget, no-progress detection); and error handling that recovers instead of compounding. Neglect any one and the loop fails in a predictable way — runs forever, drifts off-goal, or burns tokens.
Q: What is the difference between a loop and a chain?
A chain is a fixed, linear sequence of steps (A → B → C) that runs once. A loop is cyclic: it acts, observes the result, and decides whether to repeat, adapt, or stop. Agentic work needs loops because the path usually can't be fully planned in advance.
Q: What is the ReAct pattern?
ReAct (Reason + Act) is the foundational agentic loop pattern: the model alternates between reasoning about what to do and taking an action via a tool, using each observation to inform the next step. Most modern loop patterns build on it.
Q: How do you stop an agentic loop from running forever?
Use explicit termination logic: an iteration cap, a token budget, a clear verifiable goal, and no-progress detection that ends the loop if it stops moving closer to the objective.
Q: How is loop engineering related to context and harness engineering?
They're complementary layers. Loop engineering designs the cycle, context engineering manages what the model sees each cycle, and harness engineering is the entire system around the model — including the loop. Building a reliable agent means doing all three.

