
What an AI Research Agent Actually Does — and Why It's Not a Smarter Search Engine
Research done for you, not just answered — an agent that browses, cross-checks, cites, and delivers a finished brief.
What an AI Research Agent Actually Does — and Why It's Not a Smarter Search Engine
An AI research agent is an autonomous software system that accepts a research goal, breaks it into sub-questions, browses multiple sources, reads and extracts evidence from each, cross-checks facts across sources, and delivers a finished, cited brief — without a human directing every step. It is not a chatbot, not a search engine, and not a summarizer: it is a system that does the work of research rather than responding to a single question. Understanding the distinction matters because most tools marketed as "AI research" do only a small fraction of what a true agent does, and if you pick the wrong one, you end up finishing the job yourself.
Why "AI Research Agent" Means Something Specific
Language around AI tools has drifted to the point where almost anything with a search bar gets called an "agent." A rigorous definition is more useful.
A research agent must satisfy three conditions:
- Autonomy over multiple steps. It plans a sequence of actions from a single high-level goal — you do not write each search query yourself.
- Real tool use. It actually browses URLs, reads documents, and extracts text rather than generating plausible-sounding summaries from training data alone.
- A finished deliverable. It synthesizes its findings into a structured output (a brief, a report, a comparison table) with citations, not just a list of search results.
Anything that fails condition 2 is a language model pretending to research. Anything that fails condition 3 is a search aggregator. Only a system that meets all three is genuinely an AI research agent.
This definition is consistent with the academic framing behind agent architectures. The ReAct pattern — one of the foundational approaches — describes an agent as something that interleaves reasoning traces and tool actions in a loop until a task is complete (Yao et al., 2022). Research is exactly the kind of multi-step, tool-intensive task these architectures were designed for.
The Research-Agent Loop, Anatomy of a Run
The easiest way to understand what an AI research agent does is to walk through what happens when you give it a goal like: "Produce a competitive analysis of project-management SaaS tools in the construction sector, with pricing comparisons."
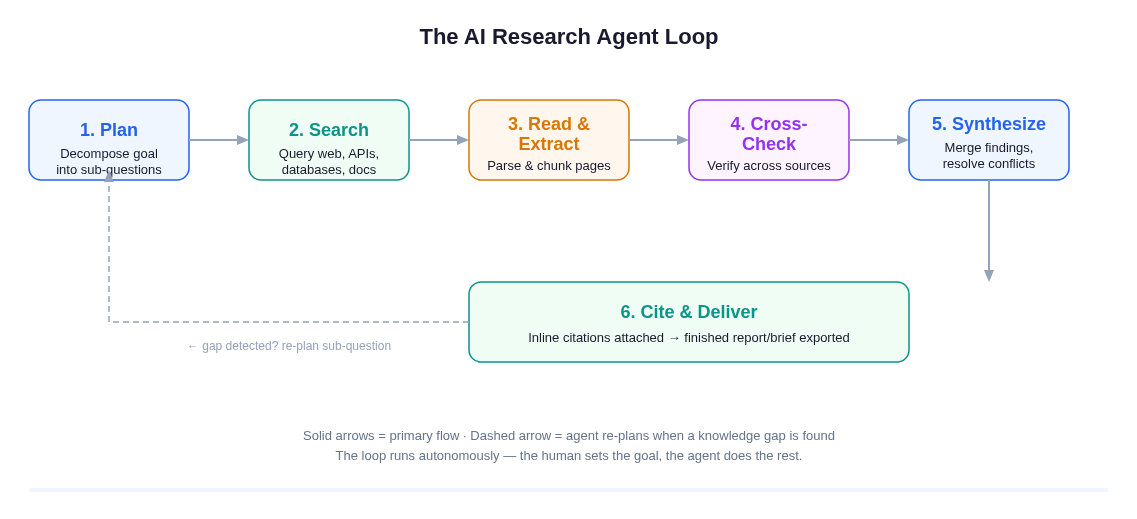 Every research agent run follows this loop. The agent re-plans automatically when it finds a gap in what it has gathered.
Every research agent run follows this loop. The agent re-plans automatically when it finds a gap in what it has gathered.
Stage 1 — Plan
The agent does not immediately start searching. It first decomposes the goal: Which competitors? Which pricing signals are publicly available? Are there industry reports? Are there review aggregators worth checking? This planning step produces a structured list of sub-questions that guides everything that follows. Without it, the agent would search randomly and miss entire dimensions of the question.
Stage 2 — Search
For each sub-question, the agent issues targeted queries — to web search, to specific domains, to databases, or to documents you have supplied. A capable agent can run dozens of queries in parallel; a weaker one does them serially and may give up after a fixed count. The quality of query formulation at this stage is a direct predictor of output quality.
Stage 3 — Read and Extract
The agent actually opens URLs, renders pages, and reads their content. It extracts structured information — feature lists, pricing tables, customer counts, executive quotes — rather than just logging page titles. This is the stage that distinguishes an agent from a search result aggregator: it has read the sources, not just found them.
Stage 4 — Cross-Check
Extracted claims are compared across sources. If one site says a tool costs $15 per user per month and another says $19, the agent flags the discrepancy and tries to resolve it by finding a primary source (the vendor's own pricing page). This step is what makes an agent's output trustworthy rather than just comprehensive.
Stage 5 — Synthesize
The agent merges evidence from all sources into a coherent narrative or structured comparison. Conflicting signals are noted rather than silently dropped. Gaps — topics where it could not find good sources — are surfaced as limitations rather than papered over with generated text.
Stage 6 — Cite and Deliver
Every claim in the final output is anchored to a source: URL, publication date, and the relevant passage. The output is a finished document — not a list of links for you to read, but a usable research deliverable.
The loop is not strictly linear. When Stage 4 reveals a gap — say, no pricing data for one competitor — the agent may re-enter Stage 1 for that specific sub-question before proceeding. The loop-back is what makes the agent autonomous rather than just automated.
Research Agent vs. ChatGPT vs. Perplexity: What's Actually Different
The comparison gets obscured by marketing, so here is the honest breakdown.
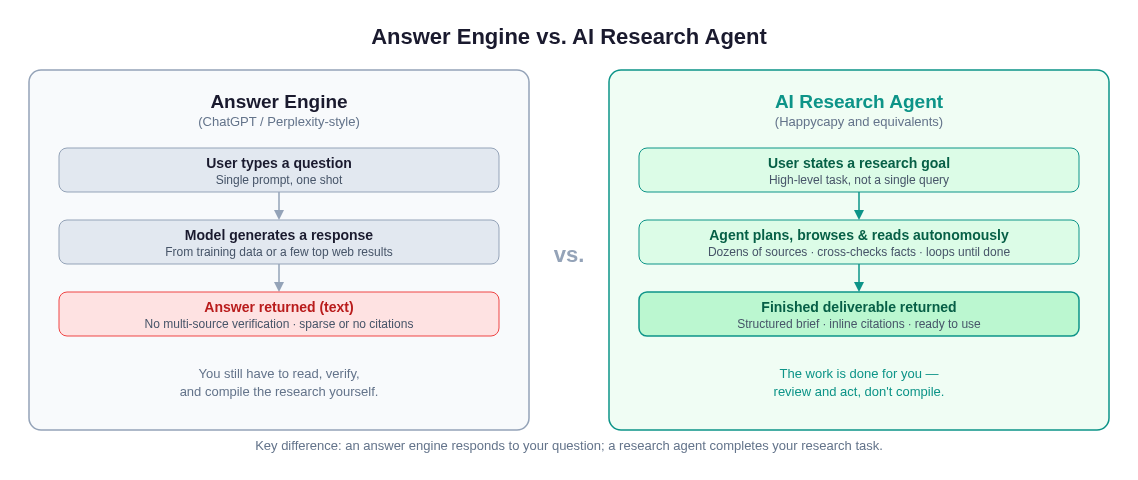 The key difference is not intelligence — it is scope of work completed.
The key difference is not intelligence — it is scope of work completed.
ChatGPT (without a browsing plugin in use) generates text from training data. It cannot browse the web in real time. Its "research" is pattern-matching from its training corpus, which has a knowledge cutoff and may not reflect current prices, current products, or recent events. It will confidently state things that were true at training time and are no longer.
Perplexity and similar answer engines do issue real-time web queries — but typically a small number (often 5–10), and they aggregate snippets rather than reading full documents. They are extremely useful for quick factual lookups. But they are built for a one-shot Q&A interaction: give a question, get an answer with citations. They are not designed to plan, iterate, and produce a deliverable. Asking Perplexity for a competitive analysis returns a paragraph; asking an AI research agent returns a structured report.
An AI research agent accepts a goal, not a question, and works until that goal is met — reading dozens or hundreds of sources, iterating when it finds gaps, and returning a structured, cited deliverable that you can hand to a colleague or file directly. It replaces hours of your time, not seconds.
The clearest way to state the difference: an answer engine responds to your question; a research agent does your job.
For a deeper look at how agents compare to chatbots at the architectural level, see our post on AI agent vs. chatbot.
What Is a Research Agent Actually Good For?
The use cases cluster around situations where you need breadth, where you need cross-source verification, or where the cost of missing something is high.
Market Research
Mapping a market — who the players are, what they charge, what customers say, where the gaps are — requires visiting dozens of sources. A research agent does this in minutes. The output is a structured market map rather than a heap of browser tabs.
Competitive Analysis
Monitoring how competitors position themselves, what features they have added, what pricing they are running requires systematic reading of their websites, press releases, review sites, and job boards. An agent can compile this into a comparison table with source citations in a fraction of the time a human analyst would need.
Literature Review
In technical or academic contexts, a research agent can survey papers on a topic, identify consensus positions, flag contradictions, and surface the most-cited works. This is especially valuable at the beginning of a new project when you need orientation without weeks of reading.
Due Diligence
Before a partnership, acquisition, or large procurement decision, you need to know what is publicly known about a company: financial signals, legal history, leadership track record, press coverage, customer complaints. A research agent can aggregate this from public sources and organize it by risk category.
Investment Research
Sector analysis, company profiling, ESG screening — research tasks that previously required a team of analysts spending days can be turned around in hours when the research legwork is automated.
Policy and Regulatory Monitoring
Organizations that need to track regulatory changes across jurisdictions can task a research agent to monitor official sources and summarize what changed and what the implications are.
For how these agent-driven workflows slot into broader business operations, see our post on AI agents in business.
A Worked Example: Running a Research Agent on a Real Task
Here is what an actual run looks like on Happycapy — an AI agent platform that accepts a research goal and delivers a cited brief from a secure cloud sandbox.
Goal: "Produce a brief on the competitive landscape for AI coding assistants — key players, feature differentiation, pricing, and which developer segments each targets."
The agent:
- Plans sub-questions: who are the major players, what are their core feature sets, what pricing models do they use, who are their stated target customers, what are reviewers saying.
- Issues queries to web search, browses vendor websites, reads G2 and Hacker News threads, checks pricing pages directly.
- Extracts structured data: feature lists, tier names, prices, integration counts, user quotes.
- Cross-checks pricing across sources — where a vendor page and a review site conflict, it notes the discrepancy.
- Synthesizes findings into a structured brief with sections per competitor, a comparison table, and a section on unserved segments.
- Attaches inline citations to every claim.
Total wall time: under ten minutes. The human's job: review the output, decide what to do with it.
What to Look for in an AI Research Agent
Not every tool calling itself a "research agent" is one. Here is a practical checklist.
Real browsing, not RAG over cached content. The agent should be browsing live URLs at run time, not retrieving from a static index it pre-populated. Stale indexes miss recent pricing changes, product launches, and news.
Source transparency. Every claim should carry a citation: URL, title, and ideally the excerpt that supports the claim. If the tool cannot show you where each fact came from, you cannot trust the output.
Multi-source synthesis, not summarization. There is a difference between summarizing a single article and synthesizing evidence across ten sources. Ask the tool to research something where sources disagree — a good agent surfaces the disagreement; a summarizer picks one version.
Iteration and re-planning. A one-pass agent is brittle. A good agent notices when its first pass missed something and loops back. Ask the vendor whether the agent re-queries when it finds gaps.
Sandbox execution. Research tasks often need code: calculating compound growth, parsing a CSV, running a script. An agent with code-execution capability in a sandboxed environment — not just text generation — can do more kinds of research. See our post on cloud sandboxes for why the execution environment matters.
Citation quality, not just citation presence. Some systems generate citations that do not actually support the cited claim, or link to pages that have since changed. Spot-check a few claims in any tool you evaluate.
Output format. Does the agent produce a structured document, or just a long essay? Tables, headers, and organized sections make the output immediately usable rather than something you have to reformat.
For a deeper treatment of what makes agent outputs trustworthy and reproducible, the AI report generator guide covers the full pipeline from data gathering to formatted export.
Honest Limitations of AI Research Agents
A well-designed research agent is powerful. It is also not infallible, and the limitations are predictable enough that you can design around them.
Hallucination on specifics. Language models can generate plausible-sounding statistics, names, or product features that do not appear anywhere in the sources they read. This is why citation transparency is non-negotiable: if you cannot trace a claim to a source, assume it may be fabricated. Good agents minimize this by only making claims they can source; some do not.
Paywalled and login-gated sources. Most research agents cannot access sources behind paywalls (academic journals, Bloomberg, Statista). If your research depends on premium databases, the agent will either miss them or tell you it cannot access them. You will need to supply those documents manually.
Dynamic content. Some web pages render content only via JavaScript in ways that basic browsing cannot capture. Agent read quality varies across site types; pages built as single-page applications may be partially read or missed.
Recency vs. depth tradeoff. An agent that prioritizes live browsing may miss older, authoritative sources that rank poorly in current search results. A good agent uses both web search and the ability to fetch specific URLs you supply.
Output length limits. Very long research tasks — systematic reviews of hundreds of papers, comprehensive market maps with 50+ companies — may hit context limits. The practical ceiling varies by platform; check before scoping the task.
Not a substitute for expert judgment. A research agent surfaces evidence; it does not make the decision. In high-stakes domains (medical, legal, financial), the output is input to a professional, not a replacement for one.
Understanding these limits is part of using a research agent well. The solution to most of them is the same: check citations, spot-verify key claims, and supply premium sources the agent cannot access on its own.
For an architectural view of how research agents manage context and avoid common failure modes, see the harness engineering guide.
Frequently Asked Questions
What is an AI research agent?
An AI research agent is an autonomous system that accepts a research goal, plans a multi-step investigation, browses real sources, extracts evidence, cross-checks claims across sources, synthesizes findings, and delivers a finished cited brief — without a human directing each step. It is distinct from a chatbot (which responds to questions) and a search engine (which returns links).
How is an AI research agent different from Perplexity?
Perplexity is an answer engine: you ask a question, it issues a small number of web queries and returns a synthesized answer with citations. An AI research agent accepts a broader goal, plans a multi-step investigation, reads full source documents, iterates when it finds gaps, and returns a structured deliverable (a report, a comparison, a brief) rather than a paragraph answer. For quick factual lookups, Perplexity is excellent. For research tasks that take a human analyst hours, an AI research agent is the right tool.
Can an AI research agent replace a human researcher?
For the legwork phase — finding sources, reading them, extracting structured data, and compiling it — a research agent can replace most of what a human researcher spends their time on. What it does not replace is domain judgment (knowing which sources are authoritative in a niche field), creative research design (knowing which questions to ask in the first place), and the contextual interpretation required in high-stakes decisions. The best framing: a research agent dramatically amplifies a researcher rather than replacing them.
How do I know if a research agent's output is trustworthy?
Check the citations. Every factual claim should link to a specific source. Spot-verify three to five claims by visiting the cited URL and confirming the claim is supported. Look at how the agent handles conflicting information across sources — a reliable agent surfaces contradictions rather than silently resolving them. If the tool does not provide source-level citations, treat the output as a starting point for verification rather than a finished product.
What research tasks are AI research agents best at?
Tasks that are information-dense, multi-source, and time-consuming: competitive analysis, market mapping, literature reviews, due diligence, regulatory monitoring, investment profiling. The larger the scope and the more sources relevant to the question, the more value an agent adds relative to doing it manually or using a single-query answer engine.
How long does a research agent run take?
On a typical task — a competitive analysis of five to ten companies, or a literature review of a defined topic — a well-built agent returns output in five to fifteen minutes. More complex tasks (comprehensive market maps, multi-country regulatory surveys) may take thirty minutes to an hour. The comparison is not to a competitor tool; it is to the human time the same task would take, which is typically measured in hours or days.
Does an AI research agent work without me providing sources?
Yes — a research agent browses the open web autonomously and finds its own sources. You can optionally supply documents (PDFs, data files, specific URLs) to augment what it finds. Supplying sources is valuable when the relevant material is behind a paywall or is a proprietary document the agent cannot access on its own.
Can a research agent run code as part of its investigation?
A good research agent can. Some research questions require computation: calculating market sizes, parsing data files, running statistical tests, scraping structured tables from HTML. Agents that run in a secure execution sandbox can write and run code as part of the research loop, not just generate text about it. This is one of the features that separates a serious research agent from a web-search wrapper. Happycapy agents run in cloud sandboxes with code execution — start free at happycapy.ai.
What is the relationship between a research agent and an AI report generator?
They overlap significantly. A research agent focuses on the investigation: finding, reading, cross-checking, and synthesizing sources. An AI report generator focuses on the output: formatting findings into a polished document with structured sections, tables, and exports. Many platforms combine both — the agent does the research and the report formatter structures the output. See the AI report generator guide for a detailed breakdown of the output pipeline.
Where to Start
If you have a research task that currently costs you or your team hours — a competitive analysis, a market map, a literature review, due diligence on a partner or vendor — the most effective first step is to run a real agent on a real task and compare the output to what you would have produced manually.
Happycapy is an AI agent platform built for exactly this. You give it a research goal; it browses, reads, cross-checks, and returns a cited deliverable in a secure cloud sandbox. You do not manage the research loop — the agent does. Free tier available, no configuration required to start.

