
PDF Processing
Comprehensive toolset to read, create, merge, split, and manipulate PDF documents with professional precision
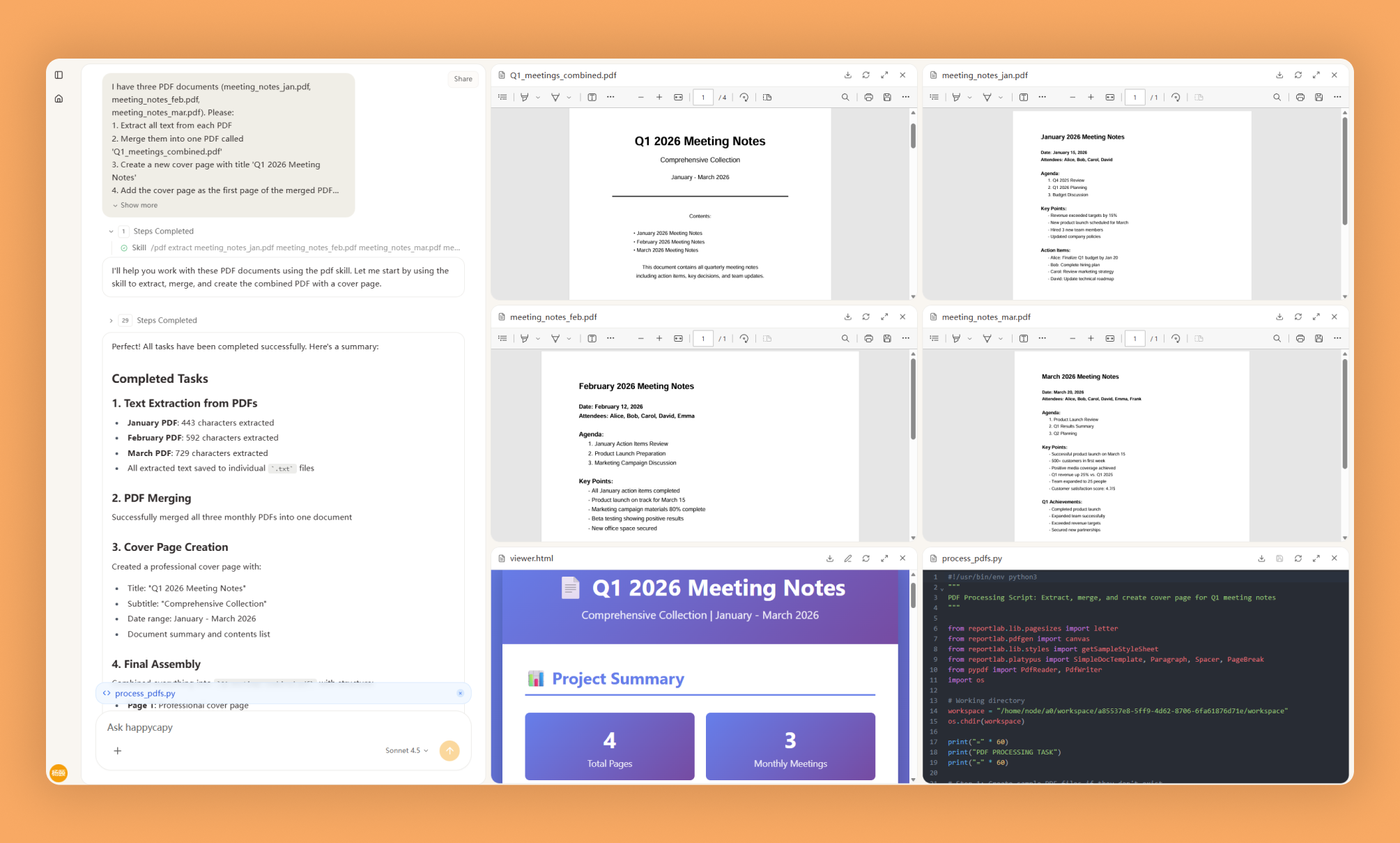
PDF documents require specialized tools for reading, extracting, manipulating, and creating content. Whether merging files, extracting tables and text, splitting documents, rotating content, adding watermarks, filling forms, or performing OCR on scanned documents, PDF operations demand programmatic solutions.
What Is This?
Overview
PDF Processing covers essential PDF operations using Python libraries. It handles reading PDFs to extract text and tables, combining multiple PDFs, splitting documents into pages, rotating orientations, adding watermarks, creating new PDFs, filling forms, encrypting or decrypting documents, extracting images, and performing OCR on scanned PDFs.
The skill uses pypdf for basic operations (merge, split, rotate, metadata extraction) and pdfplumber for text and table extraction with layout preservation. Additional tools handle form filling, encryption, and OCR processing.
This provides programmatic control over PDF manipulation enabling automation of document processing workflows at scale.
Who Should Use This
Developers automating document workflows. Data analysts extracting tables from PDF reports. Office workers merging or splitting PDF documents regularly. Compliance teams redacting or watermarking documents. Anyone processing PDFs programmatically.
Why Use It?
Problems It Solves
Manual PDF manipulation through desktop applications is time-consuming when processing multiple files. Programmatic processing automates operations, handling dozens or hundreds of documents consistently.
Extracting structured data from PDF tables manually involves tedious copy-pasting breaking formatting. Automated table extraction preserves structure and outputs data ready for analysis.
Scanned PDFs containing images of text are unsearchable. OCR processing converts these into searchable text-based PDFs enabling indexing.
Combining multiple PDF files manually requires opening each in an editor. Merge operations handle this in seconds with code.
Core Highlights
Comprehensive operations (read, create, merge, split, rotate). Text and table extraction with layout preservation. Form field filling. Encryption and decryption support. Watermark and annotation capabilities. Image extraction. OCR processing for scanned documents. Programmatic workflow automation.
How to Use It?
Basic Usage
Use Python libraries to perform PDF operations. Pypdf handles basic operations while pdfplumber excels at text and table extraction.
from pypdf import PdfReader
reader = PdfReader("document.pdf")
text = ""
for page in reader.pages:
text += page.extract_text()Specific Scenarios
For merging PDFs:
from pypdf import PdfWriter, PdfReader
writer = PdfWriter()
for pdf_file in ["doc1.pdf", "doc2.pdf"]:
reader = PdfReader(pdf_file)
for page in reader.pages:
writer.add_page(page)
with open("merged.pdf", "wb") as output:
writer.write(output)For extracting tables:
import pdfplumber
with pdfplumber.open("report.pdf") as pdf:
for page in pdf.pages:
tables = page.extract_tables()
for table in tables:
for row in table:
print(row)For splitting into pages:
reader = PdfReader("input.pdf")
for i, page in enumerate(reader.pages):
writer = PdfWriter()
writer.add_page(page)
with open(f"page_{i+1}.pdf", "wb") as output:
writer.write(output)Real-World Examples
A financial analyst receives monthly reports as PDFs with embedded tables. Using pdfplumber, they extract all tables automatically, converting them to CSV for database import. This eliminates hours of manual data entry and reduces transcription errors.
A legal team needs to merge hundreds of case documents into consolidated PDFs per case. Using pypdf merge operations, they automate this process, handling all cases in minutes rather than days.
A digitization project has thousands of scanned historical documents as image PDFs. Applying OCR processing makes these searchable, enabling full-text search across the archive.
Advanced Tips
Use pdfplumber when layout and table structure matter. Use pypdf for basic operations. Handle encrypted PDFs by providing passwords to PdfReader. For batch operations, wrap logic in loops processing directories. Cache extracted text to avoid repeated parsing.
When to Use It?
Use Cases
Automating document assembly from multiple PDFs. Extracting data from PDF reports for analysis. Splitting large PDFs into individual documents. Converting scanned PDFs to searchable text. Adding watermarks or redactions. Filling PDF forms programmatically. Rotating or reordering pages in bulk. Encrypting documents. Batch processing hundreds of files.
Related Topics
Python PDF libraries (pypdf, pdfplumber, PyPDF2). PDF format specifications. OCR engines (Tesseract) for text recognition. PDF form field types and AcroForm standard. Document encryption and digital signatures. Text extraction and natural language processing. Table detection and structure parsing.
Important Notes
Requirements
Python environment with pypdf and pdfplumber libraries. Access to PDF files requiring processing. Understanding of desired output format. For OCR, additional Tesseract installation required. For form filling, knowledge of field names.
Usage Recommendations
Install required libraries before processing. Test extraction logic on samples before batch processing. Handle encrypted PDFs by providing passwords. Use pdfplumber for complex extraction. Use pypdf for manipulation. Check extracted table structure and adjust parsing. For large batches, implement error handling. Preserve originals before manipulation.
Limitations
Text extraction quality depends on PDF structure (text-based PDFs extract better than scanned images). Table detection may miss complex layouts. OCR accuracy varies based on scan quality. Encrypted PDFs require passwords. Some advanced features (complex annotations, multimedia) may not be supported. Form filling requires knowing exact field names.
FAQ
Q: Can I merge multiple PDF files using the PDF Processing skill?
Yes, the PDF Processing skill in Happycapy allows you to easily merge multiple PDF documents into a single file using the Skills interface.
Q: Does this skill support extracting specific pages from a PDF?
With the PDF Processing skill, you can split PDFs and extract specific pages as needed. This feature is accessible through the Skills menu in Happycapy.
Q: How do I create a new PDF document using this AI agent?
You can use the PDF Processing skill to generate new PDF documents from scratch. The AI agent guides you through the creation process within the Happycapy platform.
Q: Is it possible to manipulate text or images within an existing PDF?
The PDF Processing skill provides tools to manipulate content within PDFs, such as editing text or rearranging images, all managed through the Skills system in Happycapy.
Q: Can I automate PDF tasks with this AI agent for batch processing?
Yes, the AI agent in Happycapy supports batch processing of PDFs, allowing you to automate repetitive tasks using the PDF Processing skill.
More Skills You Might Like
Explore similar skills to enhance your workflow
Redbook Creator & Publisher
Create, format, and publish engaging Xiaohongshu (Little Red Book) posts
Slack Gif Creator
Design and export high-quality animated GIFs specifically optimized for seamless sharing on Slack
Supabase Postgres Best Practices
Comprehensive guide for optimizing Postgres database performance and security using Supabase best practices
Prompt Improver
Optimize prompts for better AI responses by transforming vague requests into clear and actionable instructions
LLM Council
Multi-model LLM council with live dashboard for querying multiple AI models simultaneously and synthesizing consensus
Frontend Slides
Create stunning, animation-rich interactive HTML slide presentations