How We Rebuilt Resume Screening with an AI-Native Workflow
We ran 125 AI agents in parallel to screen 115 candidates against a consistent rubric, producing a ranked, reasoned, and fully auditable shortlist for $65.
This post is about a small experiment: hooking our Notion hiring database up to Claude Code and running a dynamic workflow that dispatches 100+ AI agents in parallel to read resumes, score them against a consistent rubric, and cross-check each other's judgments — producing a ranked shortlist we could act on immediately.
The whole thing cost $65 and ran in about 13 minutes across 115 candidates. But more interesting than the cost were the methodological questions it surfaced — when to use a fleet of agents instead of one, how to prevent AI score inflation, and what it means to encode "excellence" into something a machine can actually execute.
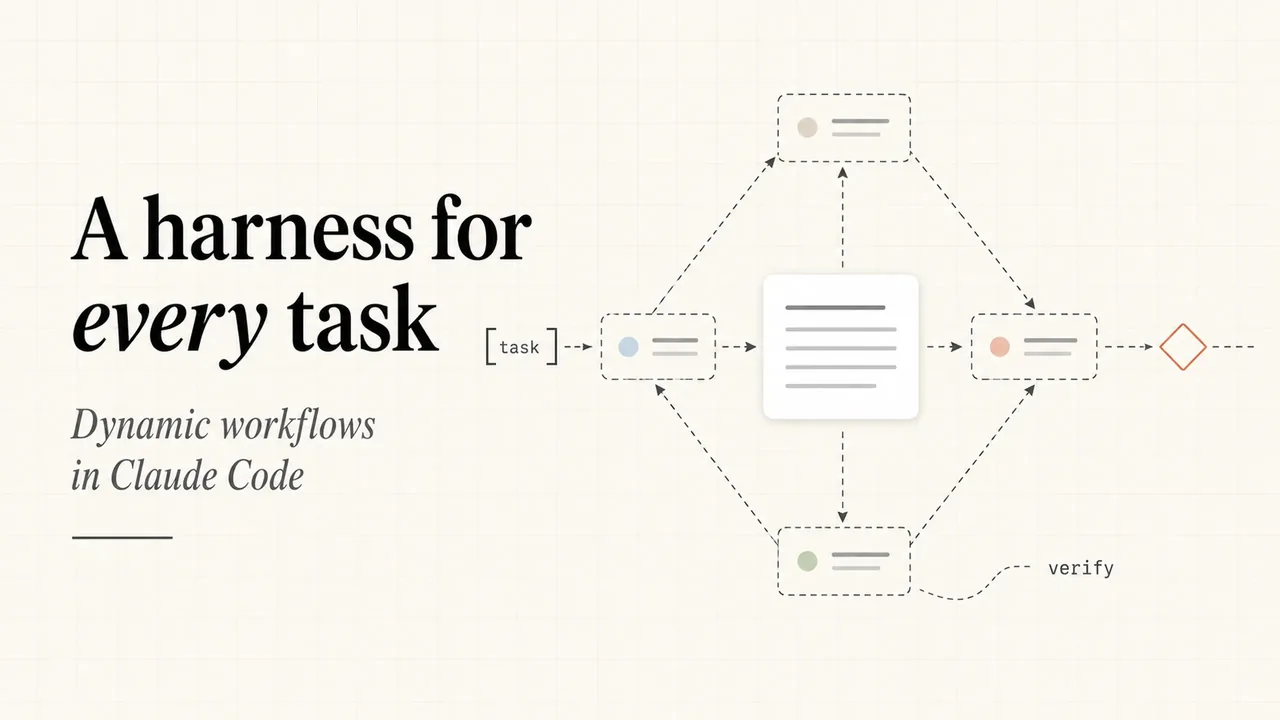
1. What Is a Dynamic Workflow
Let's start with the concept, because it's the foundation everything else rests on.
Most AI use today follows a prompt-and-reply pattern: send a message, get an answer, iterate. This works well for one-off tasks, but it gets awkward when you need to do the same thing to 115 objects — you're either copying and pasting 115 times, or asking a single conversation to process them sequentially, which gets slower and noisier as it goes.
A dynamic workflow is a different model: code that orchestrates a fleet of AI agents. Its defining properties are:
- Deterministic control flow + AI judgment, kept separate. Loops, dispatch, aggregation, and quota enforcement are handled by code (reproducible, auditable); subjective judgment (is this resume strong enough?) is delegated to AI agents.
- Fan-out parallelism. A single
parallel(...)call can spin up dozens or hundreds of independent agents simultaneously, each working on its own slice without contaminating the others. - Multi-stage pipelines. The output of one stage feeds the next. Code handles filtering, ranking, and deduplication between stages.
- Structured output. Each agent returns JSON conforming to a schema — not freeform chat text — so downstream code can consume it directly.
An analogy: a single conversation is like consulting one expert for an afternoon. A dynamic workflow is like assembling a 125-person review panel, issuing each member a rubric and one candidate file, running all reviews in parallel, cross-checking the top results, and aggregating into a ranked list — with the assembly, dispatch, and aggregation logic baked into the script.
Resume screening is a natural fit for this pattern: high volume, uniform criteria, subjective judgment, fairness requirement.
For a deeper technical introduction: A harness for every task: dynamic workflows in Claude Code
2. The Hiring Workflow: Goals and Design
The problem
We had a concrete pain point: over a hundred candidates sitting in "initial review" status in our Notion hiring database, with no realistic way to process them manually without standard drift — the bar you apply at resume 80 is almost never the same as the bar at resume 5.
I wanted to test one specific idea: can we abstract "what great looks like in the AI-agent era" into a machine-executable, human-readable rubric, and then run all 115 candidates through it at the same calibration?
The goal was explicitly not to have AI make hiring decisions. The goal was:
- Compress 115 candidates into a ranked, justified shortlist so human attention goes to the people who actually deserve it.
- Make the criteria transparent and iterable — if the output is wrong, you change a Markdown file, not code or instinct.
Three key design decisions
Decision 1: Criteria and code are completely separate
Evaluation criteria live in standalone Markdown files (criteria/), not embedded in the workflow code. Anyone — including non-technical teammates — can change screening behavior by editing these files:
criteria/
├── 00-philosophy.md Overall philosophy: what we're hiring for + the "raise the bar" rule
├── 01-pedigree.md Strong academic / early foundation (weight 20%)
├── 02-ai-agent-fluency.md AI-native capability (weight 35%)
├── 03-grit-problem-solving.md Problem-solving & overcoming difficulty (weight 30%)
├── 04-talent-lens.md Top-talent signal (weight 15%)
└── scoring.md Scoring formula + grade bands + 5% quota ruleThese four dimensions are our "excellence standard for the AI-agent era, v0.1". The thinking behind each:
- AI-native capability carries the highest weight (35%). In 2026, whether someone genuinely uses agentic tools like Claude Code as a core part of how they work is a major productivity divider. We specifically penalize keyword-stuffing — listing "Claude Code" without verifiable project evidence is treated as a weak signal.
- Hard evidence of problem-solving (30%). We look for "scar tissue": things built independently from scratch, narratives of overcoming real obstacles — not tutorial-level reproductions.
- Strong foundation (20%). Academic background serves as a proxy for raw potential — it's a signal, not a requirement. A selective-university degree paired with mediocre output gets penalized; a self-taught builder with no prestigious credential but real shipped work gets a boost.
- Top-talent signal (15%). This dimension is deliberately subjective. The prompt asks: would a team like Anthropic's or a founder like Musk immediately want to reach out? It captures agency, taste, and velocity that the other three dimensions don't.
Decision 2: Encode "raise the bar" as a hard constraint, not a slogan
scoring.md includes a firm rule: candidates reaching the top tier (S) must be ≤ 5% of the full pool. After all scoring is complete, the code applies a global cap: even if many candidates technically score in the S range, only the top 5% are allowed through. This directly fights a known failure mode — AI scoring is naturally lenient. Without a hard constraint, it will grade half the pool as "excellent."
Decision 3: Add adversarial review to catch inflated scores
Scoring alone isn't enough. A single scoring agent can get pulled along by impressive-sounding keywords — "published in top journal," "built my own framework." So the top-ranked candidates go through a second pass: a panel of "devil's advocate" agents whose explicit job is to argue against "this person deserves a top-tier rating" and push scores down wherever the evidence doesn't fully support them.
The workflow
Setup 📋 Notion hiring database — Notion CLI pull → one structured data file per candidate
AIPhase 1: Scoring (115 agents in parallel)
- Reads 6 criteria MD files + that candidate's data file
- Actively visits GitHub / portfolio links to verify evidence
- Outputs structured JSON: 4-dimension scores + reasoning + highlights + risk flags
CodeDeterministic Synthesis
- Computes weighted totals
- Global rank sort, calculates 5% quota slots
- Selects top candidates for adversarial review queue
AIPhase 2: Adversarial Review (Agents in parallel)
- "Devil's advocate" persona reviews each top candidate
- Argues against top-tier designation
- Pushes scores down where evidence is insufficient
CodeDeterministic Verdict
- Re-sorts using calibrated scores
- Enforces 5% hard cap
- Assigns final grade bands: S / A / B / C / D
Output: Ranked Report Structured Markdown with per-candidate scores, reasoning, and adversarial review verdict
Blue stages (scoring / review) are AI. Gray stages (synthesis / verdict) are code. This split is intentional: anything mathematical — weighting, ranking, quota enforcement — goes to code for reproducibility; anything requiring judgment — is this person strong enough? — goes to AI.
3. What We Saw: Results and Insights
All candidates below have been anonymized. We describe the type of work, not names or identifying details.
What we ran
| Metric | Value |
|---|---|
| Candidates | 115 (Agent Researcher / Agent Engineer / Growth roles) |
| Total agents | 125 (115 scoring + 10 adversarial review) |
| Runtime | ~13 minutes (concurrency cap ~14, completed in 8 waves) |
Distribution
| Grade | Count |
|---|---|
| S — Exceptional | 0 |
| A — Strong | 0 |
| B — Qualified | 6 |
| C — Average | 26 |
| D — Not recommended | 83 |
The 5% quota (5 slots) went completely unused — it wasn't the quota that blocked anyone; the absolute score threshold did. No one cleared the A-band floor on their own. More on why that's actually a useful signal below.
What the top of the ranking looked like (anonymized)
Without exception, the highest-ranked candidates were people who had actually built agents — not people who had heard about AI:
- #1: A graduate student who built a Claude-Code-style multi-agent workbench from scratch — including agent main loop, tool call parsing, context compression, sub-agent spawning, and safety gates. All verifiable code, not descriptions.
- #2: Another graduate student who had deployed a real, publicly accessible multi-agent system (vertical-domain application), with academic output layered on top.
- Further down: someone who wrote an agent orchestration engine in Go from scratch; someone who shipped a lightweight coding agent by studying Claude Code's architecture; someone who independently built a game with a local LLM in seven days using AI tooling throughout.
What they had in common: their strong signals almost never appeared in the resume body — they were in GitHub repos and portfolios. This is exactly why each scoring agent was instructed to actively visit links and verify evidence rather than just reading the resume text.
Three insights
Insight 1: Adversarial review genuinely caught inflated scores
The clearest example was the top two candidates. After the scoring phase, both had weighted totals around 82 points — enough to push into the A band and graze the S threshold. After adversarial review, both landed around 75 points, with very specific reasoning:
"Built a verifiable multi-agent workbench — AI-native capability is a hard signal. But the project is ~3 weeks old, single contributor, 0 stars, no tests. Conceptually a reimplementation, not original problem-solving. Almost no supporting evidence beyond the degree line: a solid high-potential candidate, but not exceptional."
"A genuine, verifiable AI-native builder. But the claimed top-journal publication appears only in recruiter notes, with no independently verifiable source. Core system backend is private; individual contribution cannot be confirmed. Using unverified academic credentials to reach for top tier is keyword-driven score inflation."
This is exactly what the design was meant to do: it didn't dismiss these candidates — it walked scores back to what the evidence can actually support. A single scoring agent can get carried away; a separate agent panel whose job is to push back deflates that reliably.
Insight 2: S:0 / A:0 is not a bug — it's a mirror
The first instinct is to ask whether the bar was set wrong. But looking at the pool honestly:
- A large fraction of candidates had very sparse resumes — key dimensions (AI experience, verifiable work) simply absent.
- Many applicants for Agent Engineer roles had zero evidence of agentic tool use and no GitHub link.
- The pool also contained recruiter business emails and LinkedIn system notifications — these were correctly identified as irrelevant and scored 0, which incidentally revealed our hiring database needed cleaning.
In other words, a strict rubric cleanly separated signal from noise. The real builders (top 6) and "accomplished generalists" (middle tier) ended up in clearly distinct places. That's the point — miss a few rather than inflate everyone.
This also surfaces an open question worth discussing: is the current A-band threshold (78 points) too harsh for candidates who are students with strong GitHub records but no professional track record yet? Interestingly, the adversarial review agents themselves described the top two as "high-potential candidates" — but the weighted score kept them in the B band. Whether to relax that threshold for high-potential early-career candidates is a judgment call best made after we see the actual interview quality from the B group. The good news: that change is one number in one Markdown file. No code required.
Insight 3: "Criteria as code" makes disagreement productive
Conversations about hiring standards usually stay vague — "we want people with drive," "someone who can figure things out." Because this rubric is written down with weights and anchoring examples, the conversation immediately gets concrete: "Should AI capability be 35% or 40%?" "How much does an outlier builder without a prestigious degree actually gain?" "Should the quota be 5% or 8%?" — every disagreement corresponds to a specific line in a Markdown file that can be changed, versioned, and debated. The standard becomes an asset you maintain, not a consensus you repeat in every meeting.
4. Cost and ROI
Exact spend
We used Claude Opus 4.8 (top tier). Precise breakdown by token category:
| Category | Tokens | Rate / M | Subtotal |
|---|---|---|---|
| Input (cache miss) | 2,306,691 | $5.00 | $11.53 |
| Cache write | 6,536,462 | $6.25 | $40.85 |
| Cache read | 12,806,404 | $0.50 | $6.40 |
| Output | 248,312 | $25.00 | $6.21 |
| Total | ~$65 |
That works out to roughly $0.57 per candidate.
A counterintuitive finding: cache writes are the biggest line item
The natural assumption is that because 115 agents are all reading the same 6 criteria files, prompt caching should help a lot. It doesn't, in the way you'd expect.
Prompt caching works on exact prefix match, and each agent session is independent. 125 agents means 125 independent sessions — each with a different task description (different candidate data) — so a cache written by agent A cannot be hit by agent B. Caching does help within each agent's own multi-turn execution (read criteria → visit GitHub → visit portfolio → output, re-reading earlier content in each round).
This reveals an architectural tradeoff: fan-out parallelism multiplies cache write costs (every agent builds its own cache), but buys you isolated, non-contaminating judgment and eliminates the quadratic context accumulation of sequential processing. For judgment-quality-sensitive tasks, that tradeoff is worth it.
How to think about ROI
Direct comparison with manual review: a hiring manager reading one resume carefully, checking the GitHub, and writing notes — conservatively 5 to 10 minutes per candidate. Across 115, that's 10 to 19 hours of focused work, with standards drifting throughout.
This workflow delivered:
| What | How good |
|---|---|
| Cost | $0.57 per candidate, full ranked output in ~13 minutes |
| Depth | Four-dimension scores, written reasoning, risk flags, and adversarial review verdict per candidate |
| Consistency | Candidate #1 and candidate #115 evaluated against the exact same rubric |
| Auditability | Complete chain of reasoning for every placement |
But the more important ROI is attentional: it redirected human focus away from the 83 clearly unsuitable candidates and toward the 6 genuine builders at the top. That's the highest-value thing initial screening can do.
Could it be cheaper?
Yes, but it probably doesn't need to be. If this became a high-frequency, high-volume operation (hundreds of candidates daily), the practical optimization would be:
- Use Sonnet for the scoring phase, Opus only for adversarial review — likely 70 to 80% cost reduction with minimal quality loss.
- Or use a cheaper model for a rough first pass, then Opus for the detailed evaluation of the top tier.
But hiring is low-frequency, high-stakes, and hard to undo. At $65 to process an entire pipeline with full auditability and iterable criteria, the conclusion is clear: use the best model. Don't trade judgment quality for marginal cost savings.
The bigger picture
What's genuinely exciting about this experiment isn't "AI can screen resumes" — that's not a new idea. It's that the dynamic workflow model — code orchestrating a fleet of AI agents — makes certain categories of work structurable, reproducible, and iterable for the first time.
Hiring is just the entry point. The same pattern — criteria as readable files + fan-out parallel evaluation + adversarial review + deterministic aggregation — transfers to any domain where you need to make consistent, high-volume subjective judgments: content moderation, code review, user feedback triage, competitive analysis, due diligence.
The rubric is v0.1. It's not perfect. But it's now a versioned, debatable, improvable asset — not an implicit agreement that lives in someone's head. That shift, more than any individual result, is what this experiment was really about.

